零、前言
在上一篇,我们介绍了使用sklearn库快速创建一个用于预测房价的机器学习回归模型,并通过平均绝对误差、均方差和R3分数有效地评估了这个预测模型的效果。
在本篇,我们继续介绍借助sklearn库创建用于进行分类预测的机器学习模型。
对分类问题进行预测同样属于监督学习的范畴,通过对已知数据的类别的标记,来实现对未知数据的类别的预测和判定。
常见的应用领域包括:垃圾邮件识别、垃圾短信识别、图像分类识别等等。
常见的应用算法则有:SVM(支持向量机)、K紧邻、朴素贝叶斯、随机森林等等。
下面,我们就通过Digits手写数字集来进行机器学习分类模型的介绍。
一、初探手写数字数据集
本篇选用的手写数字数据集同样来自有sklearn.datasets子模块,其由著名的UCI 机器学习库提供:

该数据集由1797个8×8图像组成。每个图像,都是手写数字。
就像上一篇导入波士顿数据集一样,我们从sklearn模块中进行导入:
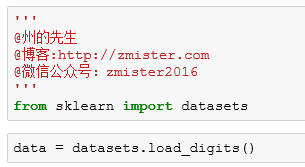
接着查看数据集中包含的子方法:

与波士顿数据集类似,其提供了images、target_names、target、data、DESCR等方法。其中:
- images:表示图像的原始数组;
- target_names:表示图像分类中所有的数字;
- target:表示图像数组对应的数字名称;
- data:表示图像的一维特征数组;
- DESCR:表示数据集描述信息;
从这两个数据集可以发现,sklearn的API还是挺统一和规范的,很方便进行学习和调用。接下来,我们看看每个方法中到底都是些什么。
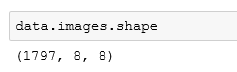
通过查看images的形状,以及已知的图像为8×8的形状,我们可以得知,这个数据集中有1797个图像。看看其中一个图像的内容:
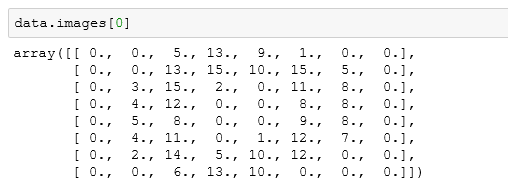
这就是一个图像转换成数组之后的形式,我们怎么知道这是个什么图像呢?可以借助于matplotlib模块来将图像数组还原为图像。
可能之前搭建环境的时候没有安装这个模块,我们先来安装一下:
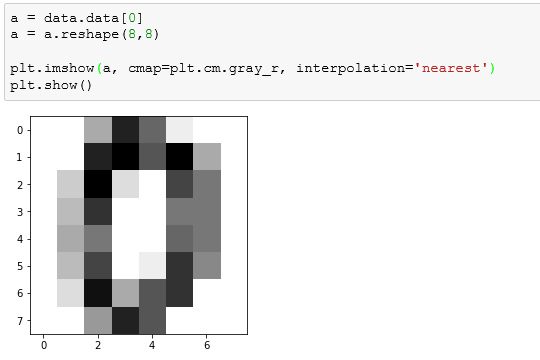
然后引入matplotlib模块,调用imshow()方法:
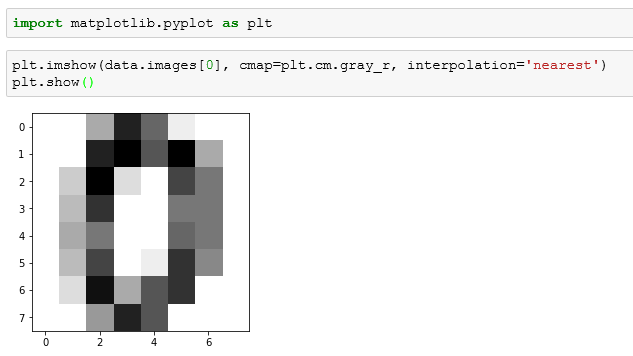
可以发现,iamges中的第一个图像似乎数字0。我们继续看下面的内容。

data的target_name信息显示,我们的数据代表的数字分类类别为0到9。
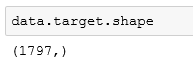
数据的目标值与数据集时匹配的,最后再看看data的data:
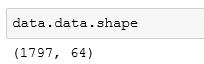
数据量还是1797条,但是形状已经从二维的(8, 8)变成了一维的64,我们从一个具体的数据中看看:
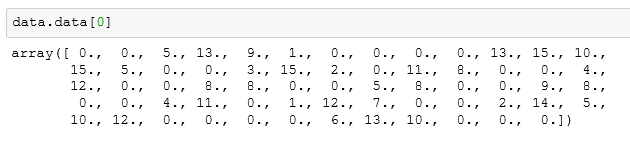
可以发现,data.data中的数组将之前8*8的数组合成为了一个数组,这样才能方便对图像的数组运用算法进行训练和计算。那又如何将一维的图像数组还原为图像呢,通过是上面的方法,但是需要先将一维数组转换一下形状:
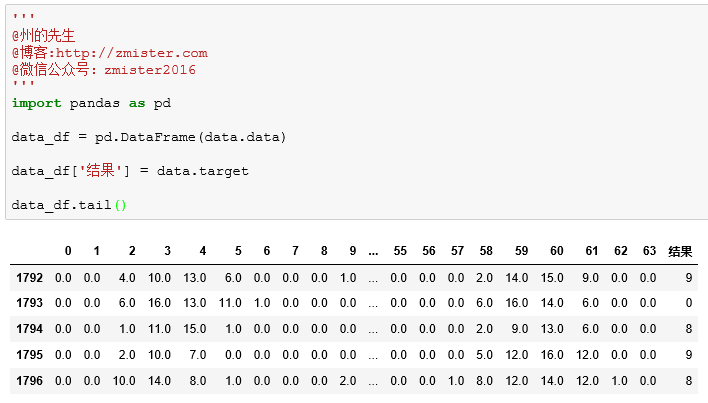
我们同样将数据集的特征和目标转换为pandas的DataFrame,方便各位同学理解数据集的形状:
二、分割训练测试集
同样使用sklearn提供的train_test_split方法来对数据集进行训练集和测试集的分割:
三、创建分类模型
在此,我们同样选择随机森林算法 作为机器学习模型估计器的基本算法来创建一个机器学习分类器并进行训练:
四、评估模型
在训练完成模型之后,我们同样可以使用模型的predict()方法获取到测试集的预测结果:

在面对回归模型的时候,我们可以使用平均绝对误差、均方差等方法对模型的效果进行评估,而在分类算法模型中,我们使用其他的方法进行模型效果的评估,比如:精度分类评分、召回评分等。而这些方法,也都在sklearn模块的metrics子模块下。
我们来对分类模型进行效果评估:
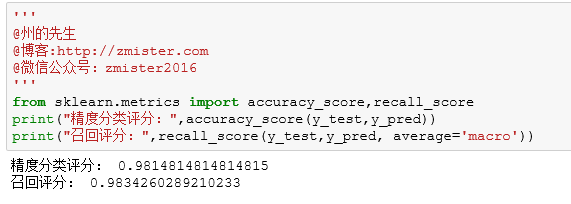
两种评估方法的最佳结果值都是1,看起来我们的模型准确度还是蛮高的,大家可以尝试其他的算法构建分类模型。
下一篇,我们将介绍构建一个聚类预测型。
文章版权所有:州的先生博客,转载必须保留出处及原文链接