舆情监控系统在过去几年曾是一个比较热门的话题,一般多被应用在政务领域、企业领域等,用于让企业、部门等单位及时获取和了解到网络上舆情的出现和发展,以便及时采取相应的措施,从而控制舆情、引导舆情,化危为机。
最近生意参谋在服务洞察栏目里面也上线了一个商家版的舆情监控系统,州的先生(https://zmister.com)看了一下,发现这套东西完全能够使用Python从数据源采集到数据处理和分析,到最后对外部展示交互,进行全链路的开发。
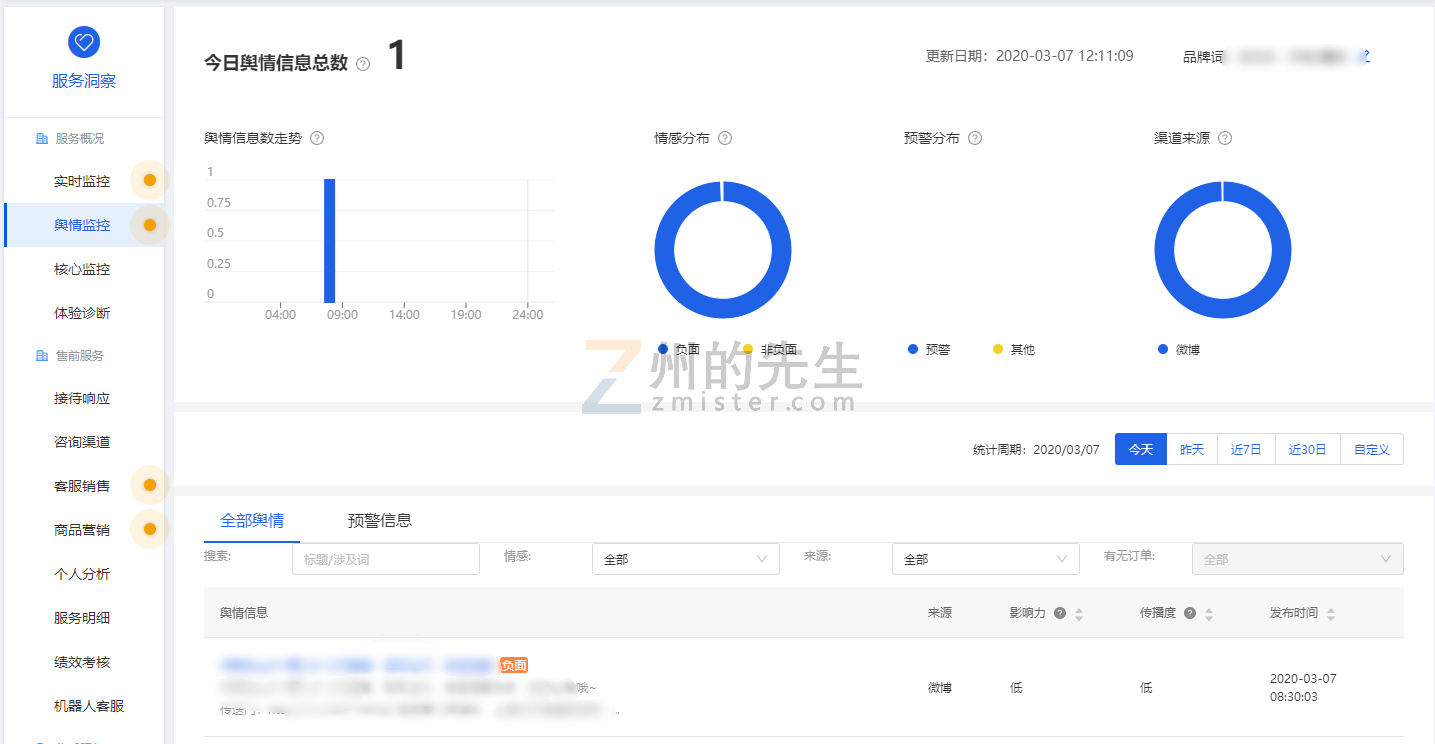
思考了一下,于是有了这个使用Python实现全链路的舆情监控系统的设计思路。下面一一进行介绍。
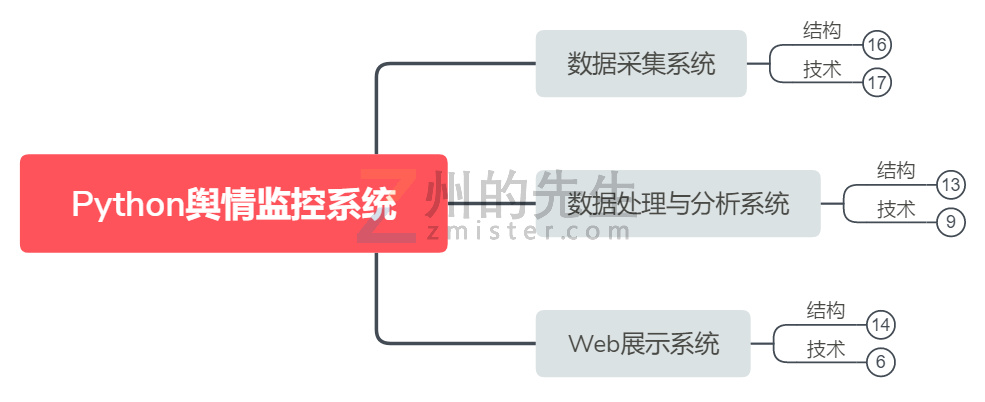
一、数据源系统
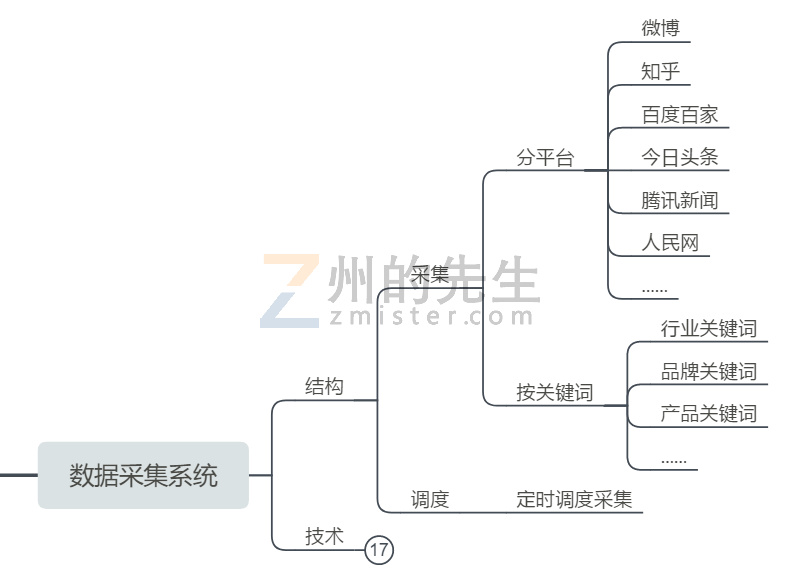
数据,是一个舆情监控系统的基础,没有数据,一切监控都无从谈起。对于舆情系统而言,数据源主要来自于各大媒体、新闻、论坛等网站,包括但不限于微博、知乎、今日头条、百家号、公众号等等,特定行业可能还会有更特定的垂直网站来源,比如小红书、什么值得买、虎扑等。
舆情系统需要从这些网站中获取数据,获取哪些数据呢,如果是一个公司,它可能会关注行业和市场相关的词、自己品牌相关的词、自己产品相关的词。比如一个从事汽车行业、卖汽车的企业,它会去关注国家政策对汽车行业的变化(排放标准)、地方对汽车相关的政策措施(限号、新能源补贴)、某个品牌汽车的丑闻、某款汽车型号的最新研究(中保研碰撞测试)等等。
所以我们的舆情系统应该以数据源平台为根基,以关键词为核心,按照一定的频率,对数据进行采集。
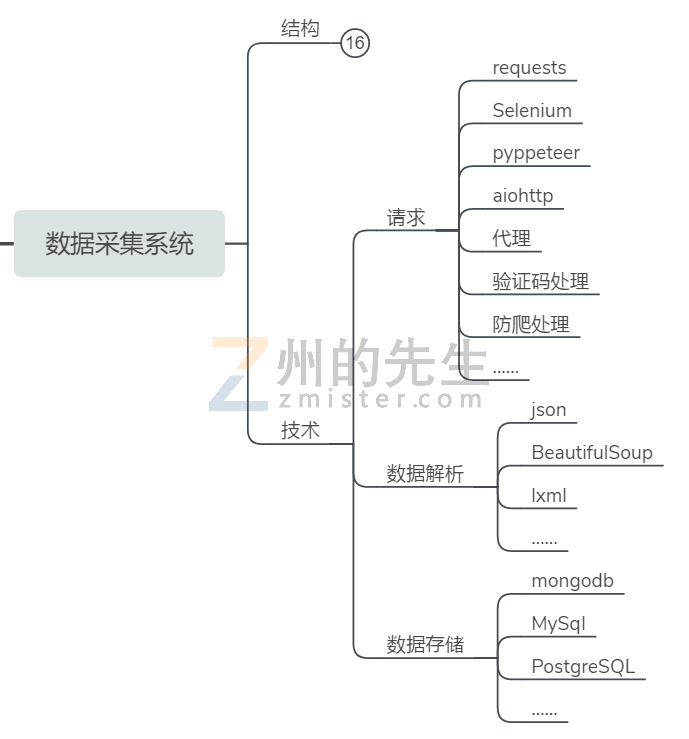
而数据采集,是Python这门编程语言的一个强项。其拥有丰富且强大的各种模块用于进行HTTP请求、数据解析和数据存储。
在HTTP请求方面,可以根据不同平台和网站的特点,灵活地使用requests、Selenium、Pyppeteer、aiohttp。在这个过程中可能会遇到反爬虫机制,比如IP限制、数字验证码、滑块验证码、点选验证码等等,那么可以使用代理IP、验证码破解等技术。
简单的数字验证码可以使用tesseract进行训练识别,拼图滑块可以使用OpenCv和YoLo进行目标检测,在此仅一两例而已。
甚至于在某些情况下,可以使用MitmProxy这个本地代理服务器模块,篡改相关的请求和响应,以绕过验证。
能够请求成功,获取到页面和数据之后,解析就比较轻松了,JSON、LXML、BeautifulSoup等模块都能够比较好的进行数据的解析,方便为数据入库做准备。
最后的数据入库,数据库的选择可以有很多,Python都能很好地对各类数据库进行操作。MongoDB、MySQL和PostgreSQL是州的先生比较中意的3个。
二、数据处理和分析系统
数据采集完成,存储到数据库之后,就该进行数据处理和分析了。这是承前启后的一步,承接采集的数据,开启前台页面的功能支持。
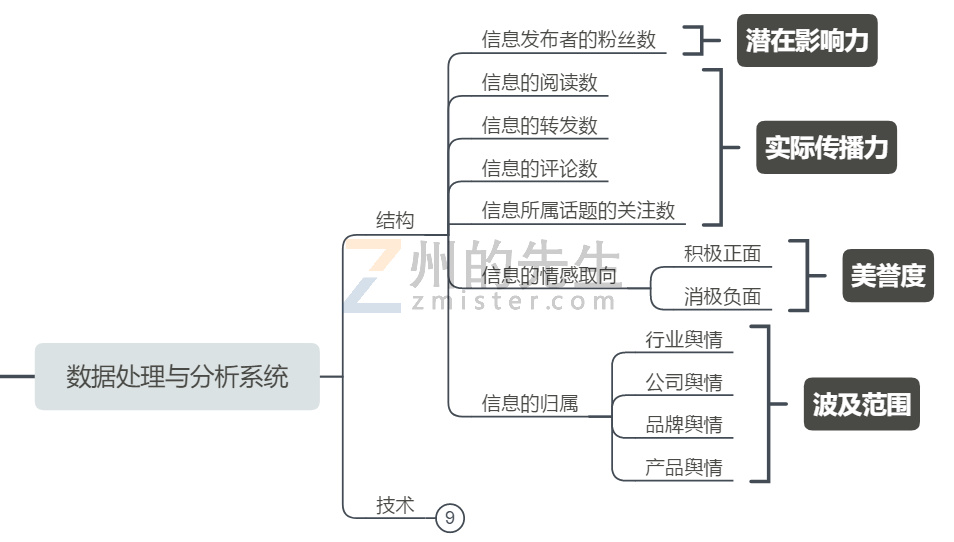
我们需要处理和分析哪些内容呢?州的先生(https://zmister.com)对信息的价值按照潜在影响力、实际传播力、美誉度、波及度划分了五个维度来归类和整理数据。
潜在影响力涉及到信息发布者的粉丝数等,用来衡量一个舆情在初始状态下潜在的影响范围。潜在影响力低的舆情不代表就是不重要的舆情,如果后期经过社交转发和跟踪报道,产生了裂变,其实际的传播力就会很高。
实际传播力涉及到信息的阅读数、信息的转发数、信息的评论数、信息所属话题分类的关注数等。不同于潜在影响力的静态值,实际传播力是一个容易动态变化的值,需要密切跟踪。
美誉度来自于信息的情感态度取向,一个文章是赞美还是批评,是吹还是黑,一个知乎问题下面的回答是骂的多还是夸的多,这些积极正面或是消极负面的态度都会影响美誉度。
波及度则是根据信息的归属来划分,看其是全行业的舆情、还是只是公司的舆情、或者只是影响到某一个产品。当然,波及度也不是动态不变的,如果一个产品的问题爆发出来,迟迟得不到解决,原本这个波及度仅仅局限在某个产品的舆情会扩展到整个公司。
再来看如何用Python分析和处理上述提及的5个维度。从上面我们可以看到,目前这些数据的基本可以归为2类:
- 数据统计处理
- 自然语言处理
对于数据统计处理分析,Python的数据处理模块Pandas基本就能胜任。后期如果数据增长到使用Pandas影响效率,可以加入Dask进行数据处理。
对于自然语言处理,Python有一个很经典的NLTK库用作自然语言处理,对于中文来说,分词是必不可少的。Python中有很多用于中文分词的模块,Jieba或者其他的选择。
同时,目前各家大厂都有开放自然语言处理的接口供开发者使用,如果不想自己训练和处理自然语言处理,调用这些大厂的接口也是一个选择,比如百度AI、阿里云AI、华为AI、BosonNLP等。

三、前台展示系统
在对数据进行处理分析完成之后,我们就需要构建一个前台系统供用户使用。对于前台系统,目前常用的有桌面客户端和Web网站两种。
不管是那种前台系统,我们的舆情系统都应该先考虑如下问题:
- 用户需要输入什么?
- 用户可以看到什么?
这两个问题将支撑整个舆情系统的前台界面。
用户需要输入什么?用户只需要输入他想监控的关键词即可,剩下采集、分析、调度、报告生成都交给后台来处理。
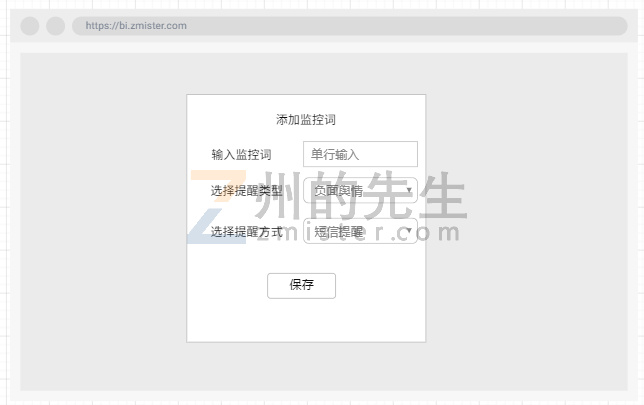
用户能够看到什么?
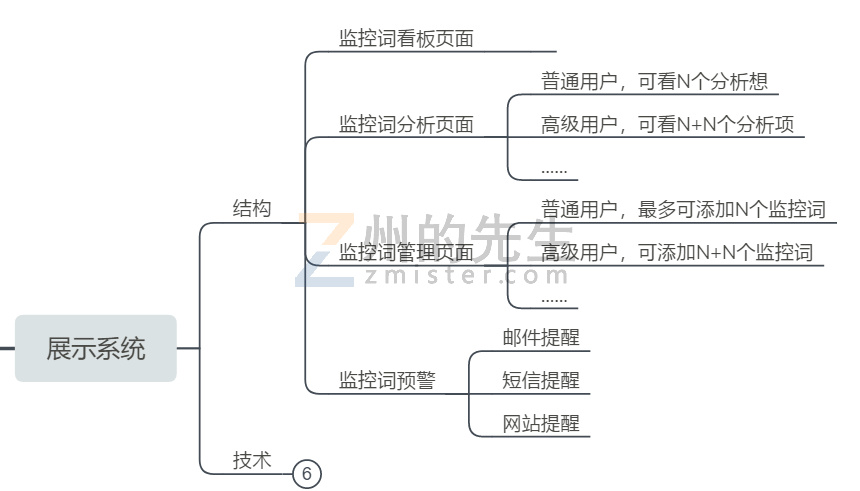
舆情总览看板,用于总览用户所有监控词的状态,包含分布、趋势、数量、系统评级等。
单个监控词的监控详情,包含此监控词的当前舆情状态、日趋势、周趋势、月趋势、词云,相关的每一条数据来源、内容、潜在影响力、实际传播力、美誉度和波及度。
监控词管理,用于用户管理自己添加的监控词。

可能在实施过程中会产生其他的想法,目前来说,一个总览页面、一个监控词详情页面、一个监控词管理页面,就是这个舆情监控系统的主要组成部分了。基于此3个页面而生的一些配置页、管理页,暂时不算入 其中。
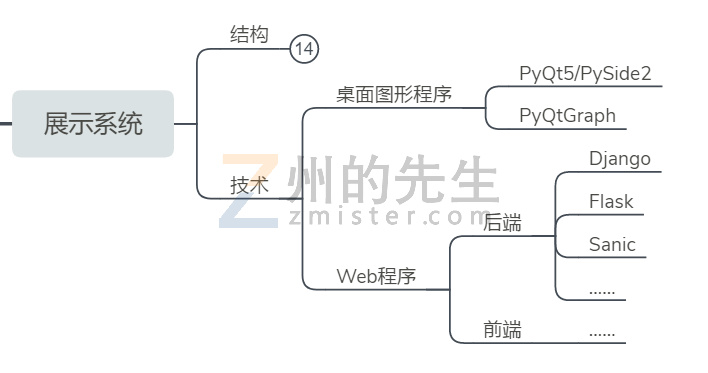
对于实现方式而言,上面我们说过,有两种形式:桌面客户端和Web网站。虽然桌面客户端逐渐式微,但我们也将其考虑在内,毕竟桌面客户端在某些场景下的优势是Web网站无可比拟的。
幸运的是,Python无论是开发桌面图形程序,还是开发Web程序都有很成熟稳定的方案。
如果是开发桌面图形界面程序,那么可以选择PyQt5/PySide2进行。考虑到系统会有大量的图形渲染及其他外部调用,Python内置的Tkinter就排除在外了。同时对可视化的操作可以通过Qt的Chart来绘制,也可以使用PyQtGraph来绘制。
如果是开发Web网站,那么Django、Flask、Sanic等Web框架都是可以考虑的后端框架,前端的页面展示,各类前端框架和前端UI库都是可以考虑的对象。
四、最后
这就是一整个使用Python实现全链路舆情监控系统的设计思路了。如果有不同的想法或是思路,欢迎留言讨论~
文章版权所有:州的先生博客,转载必须保留出处及原文链接
写的很棒,留言点赞
思路有了,有没有现成的程序
思路不错,已经实现了吗?