何谓“真实场景”,意即图片验证码来源于实际的数据采集过程中遇到的网站,对图片验证码的识别训练工作也是出自于真实的环境,而非像很多文章用一个验证码库生成好几万个验证码图片样本,然后用一个CNN或LSTM模型,把数据扔进去跑。看着是过瘾,测试效果也很好,然后呢?照着做碰一鼻子灰!
文章目录
一、验证码采集
既然要识别验证码,那么一定数量的验证码图片样本必不可少。我们的验证码图片就存在于网站(具体是什么网站就不透露了)之中,图片验证码的显示形式有以下几种:
- 一个URL每次访问都生成不同的验证码图片并显示;
- 每次访问都是一个随机的URL生成验证码图片并显示;
- 验证码图片以base64编码的形式返回并显示;
对于这几种验证码图片,采集的手段也有很多种。州的先生(https://zmister.com)采用的是直接通过Selenium+Firefox对验证码图片进行截图保存的形式。一共采集了几百个验证码图片,如下图所示(已经通过图片标注软件标注好了):

二、验证码标注
验证码下载好了之后,我们需要对其进行标注。在这里,州的先生(https://zmister.com)使用的是之前自己写的一个验证码图片标注软件:
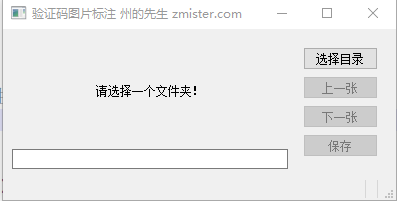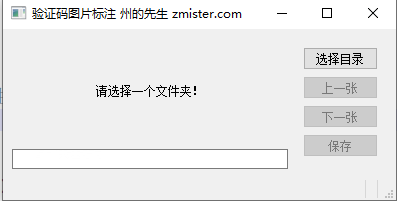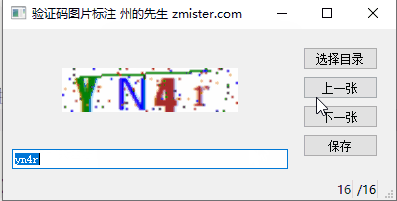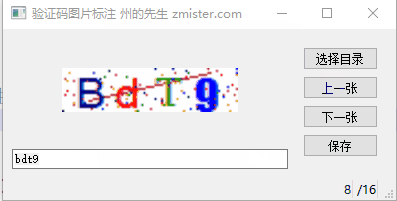
具体的链接请戳:https://zmister.com/archives/1370.html。
三、验证码降噪
可以看到,这些验证码有不同的背景颜色、不同位置的干扰线、字体也是不一样的,为了便于训练和识别,我们先对这些验证码图片进行降噪处理。
对于图片的降噪处理,州的先生在之前也发表过一篇文章来介绍,请戳这里:https://zmister.com/archives/1342.html
在这里,我们主要进行了二值化降噪和邻域降噪,顺便对验证码图片的大小进行了裁剪,最后得到降噪后的验证码图片如下图所示:

四、将图片转为TIF格式
上面我们采集和处理的验证码图片文件都是PNG格式的,为了后续处理,我们将其转为TIF格式。转换的方法也很简单,使用Python的PIL库,读取图像然后另存为tif格式就可以了,代码如下图所示:

最后我们得到所有格式为tif的验证码图片文件,如下图所示:

五、合并TIF格式验证码为一个TIF文件
在把所有验证码图片从PNG格式转为TIF格式之后,我们继续把这个TIF格式的验证码图片合并为一个TIF格式文件。合并的方法,州的先生采用的是jTessBoxEditor这个软件。
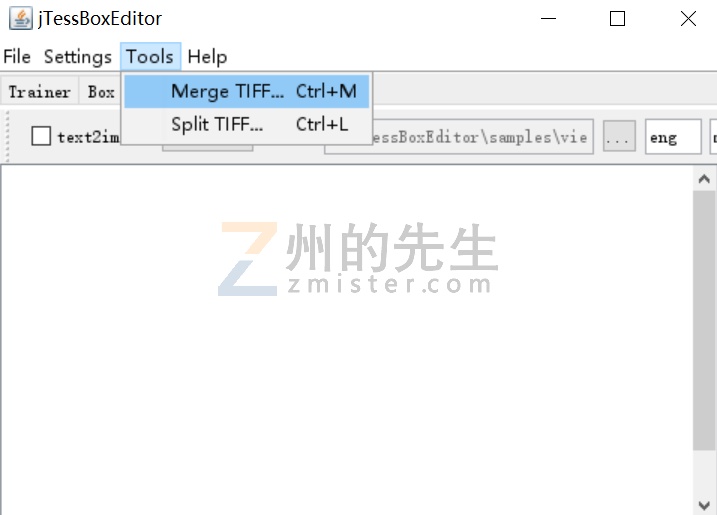
点击菜单栏的“Tools”按钮,选择“Merge TIFF”,在打开的文件选择框中选择所需合并的验证码图片。
最后,我们几百个TIF格式的验证码图片合并为了一个TIF文件,如下图所示:
为了进行后续的操作,合并后的文件名需要按照一定的规则来命令:
[lang].[fontname].exp[num].tif
其中:
- lang表示语言名称;
- fontname表示字体名称;
- num表示序号
在这里,我们将TIF的文件名保存为了:cqc.font.exp0.tif
六、生成TIF图片的box盒子文件
生成box盒子文件是为了标识出图片中文字的具体位置。如果要训练进行训练,我们必须得准备tif/box这一文件对。在此,我们通过Tesseract的makebox命令来生成box盒子文件,其命令为:
tesseract cqc.font.exp0.tif cqc.font.exp0 batch.nochop makebox
在命令行中运行此命令,我们将会得到一个和TIF文件同名的box文件:cqc.font.exp0.box

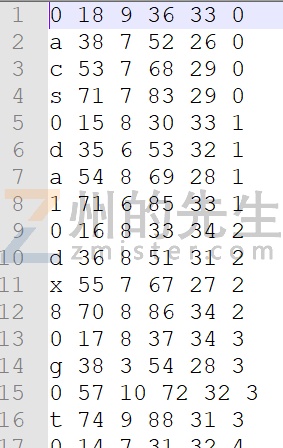
打开box文件,可以发现其都是各个字符框的坐标:
由于box盒子文件生成的方式有很多种,Tesseract4.0也接受多种格式的box盒子文件,但是并不支持makebox命令生成的box盒子文件。根据Tesseract官方在GitHub上列出的说明和示例文件(https://github.com/tesseract-ocr/tesseract/issues/2357)来看,问题主要出在其他命令生成的盒子文件会在换行的文本同EOL标识,以表示下一行的文本,而makebox命令则不会生成换行标识符。但是在这里,我们的验证码图片就是一行文本,不需要换行,所以在此场景下,makebox生成的box盒子文件也是可用的。
七、补充和修正box盒子文件
Tesseract4.0与之前版本对于box盒子文件要求的区别在于,在Tesseract4.0中,不再要求box盒子文件中对文本的框选精确到单个字符,只需要将框的位置覆盖到一行文本即可。
但是为了便于训练,我们还是选择对单个字符进行框选。同时,makebox命令生成的box盒子文件不一定是完全无误的,有一些图片可能就没有识别出盒子框来,而jTessBoxEditor这个软件只能对已存在的box信息进行处理,没有办法在缺失box信息的图片上新增box。这时候需要我们人为对生成的box盒子文件进行一些处理。
先对缺失的盒子填充默认值,在之前的步骤中,我们使用文本编辑器打开过box文件,其内容为图片内字符的框选坐标,一共有6列,分别为:字符名称、X轴坐标、Y轴坐标、字符宽度、字符高度、所处的图片位置。比如:
0 18 9 36 33 0 a 38 7 52 26 0 c 53 7 68 29 0 s 71 7 83 29 0 0 15 8 30 33 1 d 35 6 53 32 1 a 54 8 69 28 1 1 71 6 85 33 1 0 17 8 37 34 3 g 38 3 54 28 3 0 57 10 72 32 3 t 74 9 88 31 3
上面的内容就表示,第1个图片的4个字符(0acs)、第1个图片的4个字符(0da1)和第3个图片的4个字符(0g0t)的位置信息,其中缺了第3个图片的信息。

然后打开之前的JTessBoxEdit软件,点击“Box Editor”选项卡,加载TIF文件对box进行修改(box文件和tif文件需要在同一个文件夹下):
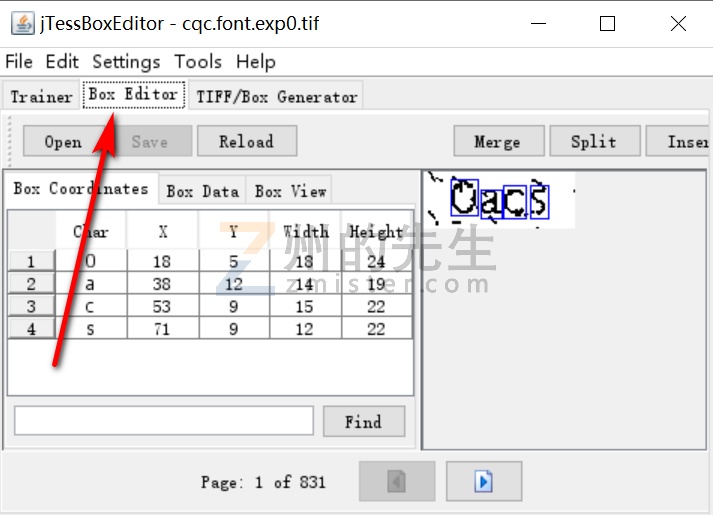
对box修改好之后。我们就可以进行下一步了。
八、生成lstmf文件
这一步,我们通过TIF图像文件和box盒子文件生成进行LSTM训练所需的lstmf文件,使用到的命令如下所示:
tesseract cqc.font.exp0.tif cqc.font.exp0 -l eng --psm 6 lstm.train
运行之后,我们的文件夹下会生成一个名为cqc.font.exp0.lstmf的文件。
九、提取语言的LSTM文件
我们接着从tesseract_best(链接:https://github.com/tesseract-ocr/tessdata_best)下载相应语言的traineddata文件。在前面几步,我们选用的语言是英文,所以在这里选择eng.traineddata文件。

下载好之后,我们需要从中提取中它的LSTM文件,使用的命令如下所示:
combine_tessdata -e eng.traineddata eng.lstm
运行上述命令,我们的文件夹下会生成一个名为eng.lstm的文件。
十、训练
在完成了上述步骤之后,我们基本上可以开始LSTM的训练了。但是还缺了一步,我们新建一个名为eng.training_files.txt的文本文件,在里面填入第八步生成的lstmf文件的绝对路径。
然后,使用下面的命令就可以开始训练了:
lstmtraining \ --model_output="D:\cqc_train\output\output" \ --continue_from="D:\cqc_train\eng.lstm" \ --train_listfile="D:\cqc_train\eng.training_files.txt" \ --traineddata="D:\cqc_train\eng.traineddata" \ --debug_interval -1 \ --max_iterations 4000
各个参数具体的含义,可以参考Tesseract官方对于4.0如何进行训练的说明(链接:https://tesseract-ocr.github.io/tessdoc/TrainingTesseract-4.00)
待Tesseract训练完成之后,在output文件夹下会有很多checkpoint记录文件。我们接着使用命令把这些文件和之前的eng.traineddata合成为新的traineddata文件,使用命令如下:
lstmtraining \ --stop_training \ --continue_from="D:\cqc_train\output\output_checkpoint" \ --traineddata="D:\cqc_train\eng.traineddata" \ --model_output="D:\cqc_train\output\cqc.traineddata"
运行训练不到10分钟就完成了(具体的训练时间要视训练集的大小和训练次数决定),在文件夹下会生成一个名为cqc.traineddata的文件,我们将其复制到Tesseract-OCR的tessdata文件夹下,就可以使用其作为一个语言进行文字识别了。
最终,我们的文件夹下有如下图所示的文件:

里面包含了我们各个步骤下创建、生成和提取出来的文件。
十一、测试
在训练完成得到新的语言文件之后,我们对其进行测试一番。为了更明显地查看训练的效果,我们同时使用Tesseract的传统识别模式、Tesseract的LSTM识别模式和采用训练得到的语言文件的LSTM识别模式。

前两种都是使用英语进行识别测试,后一种使用训练出来的cqc语言进行训练。我们分三次从1000张测试图片中随机选择100张图片进行识别测试,然后计算3个类型的平均测试准确率:

def work(self):
for i in range(3):
self.check_single()
print('总数:',self.n)
print('传统识别模式:',self.n1/self.n)
print('LSTM识别模式:',self.n2/self.n)
print('LSTM训练模式:',self.n3/self.n)最终我们得到3个类型测试效果的结果如下所示:

可以发现,通过LSTM训练之后的验证码识别成功率在75%以上,这还仅仅只是831张图片训练出来的效果。而传统的识别模式只有18%,就算是系统自带的LSTM识别模式,也只有28%的识别成功率。
如果将训练集的数量再增加一些,可以预计识别成功率还会更加高。
到此,本篇文章就结束了,欢迎留言讨论!
参考链接:
Tesseract官方关于使用makebox配置生成的box文件不支持Tesseract4的LSTM训练的说明链接:
https://github.com/tesseract-ocr/tesseract/issues/2357
在官方介绍中,Tesseract4的训练数据所需的格式和tesseract3一样,仍然是tif+box文件,但是并不需要box文件里面的框只需要覆盖到每行文本即可,不再必须覆盖每一个字符;
https://github.com/tesseract-ocr/tesseract/wiki/TrainingTesseract-4.00
jTessBoxEdit软件不能在不存在盒子的图片中插件盒子,所以需要使用Python脚本对一些不存在盒子的图片默认新增几个盒子,问题链接:
https://github.com/nguyenq/jTessBoxEditor/issues/15
文章版权所有:州的先生博客,转载必须保留出处及原文链接