在互联网上的各类网站中,无论大小,基本上都会有一个搜索框,用来给用户对内容进行搜索,小到站点搜索,大到搜索引擎搜索。
从简单的来说,搜索功能确实很简单,一个简单的 select 语句就可以实现数据的搜索。
而从复杂的来看,无论是搜索的精度还是搜索的效率,都是有很深的研究范围的。
对于简单的搜索功能来说,一个 select 查询语句也足够使用,但在稍微复杂一点的搜索环境下,比如网页、文档、新闻资讯等场景,单纯的 select 查询语句则是远远不够。在这些场景下的搜索,全文搜索则是最低配置。
什么是全文搜索?百度百科如是说:
全文数据库是全文检索系统的主要构成部分。所谓全文数据库是将一个完整的信息源的全部内容转化为计算机可以识别、处理的信息单元而形成的数据集合。全文数据库不仅存储了信息,而且还有对全文数据进行词、字、段落等更深层次的编辑、加工的功能,而且所有全文数据库无一不是海量信息数据库。
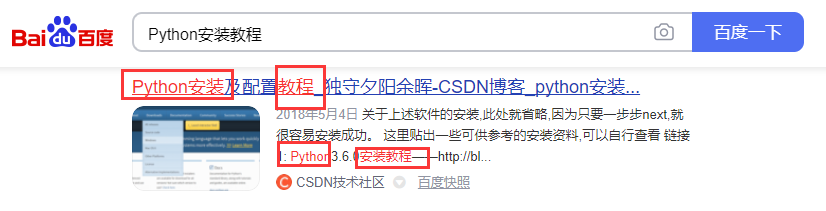
是不是看得不明不白的?讲一个简单的例子大概就理解了。正常情况下,我们搜索“Python 安装教程”,如果是普通的搜索,会直接使用 select 数据库中包含“Python 安装教程”的内容。但是全文搜索,会首先将搜索词拆分成:“Python 安装教程”、“Python”、“安装教程”、“安装”、“教程”等,然后用这些拆分后的词组进行搜索。
市面上所有的搜索引擎都使用了全文搜索:
最近“MrDoc 交流群”里让觅道文档添加上全文搜索的呼声很高,遂打算在觅道文档中把常规的 select 查询搜索替换为全文搜索。
最常见的开源全文搜索引擎是 Elasticsearch,功能强大、性能强悍,但是其基于 Java 进行编写,在 Python 中使用不是很方便,最终州的先生选择了纯 Python 实现的全文搜索引擎——whoosh,并借助 Django 下的开源搜索框架——haystack,依靠 jieba 中文分词库,在觅道文档这一典型 Python Web 应用中实现了中英文的全文搜索。
安装依赖库
如上述所言,本次纯 Python 方案实现中英文全文搜索使用到了如下 3 个库:
- whoosh
- haystack
- jieba
需要对其进行安装,使用 pip 命令进行安装即可:
pip install whoosh
pip install django-haystack
pip install jieba
settings 配置
首先需要在 Django 项目的 settings.py 文件中进行配置。
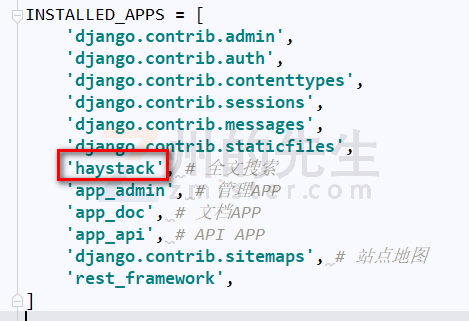
第一、在 INSTALLED_APPS 中添加 haystack 库:
第二、添加配置 haystack 的配置项
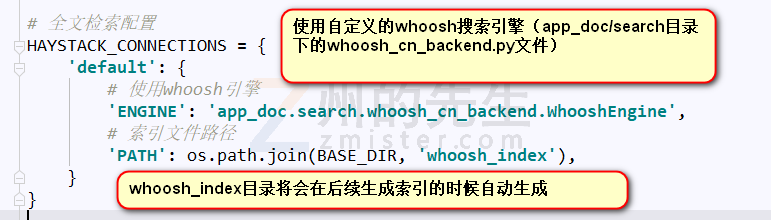
# 当添加、修改、删除数据时,自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
# 自定义高亮
HAYSTACK_CUSTOM_HIGHLIGHTER = "app_doc.search.highlight.MyHighLighter"
创建索引
在 app_doc 目录下新建一个名为 search_indexes.py 的文件,在其中输入如下内容:
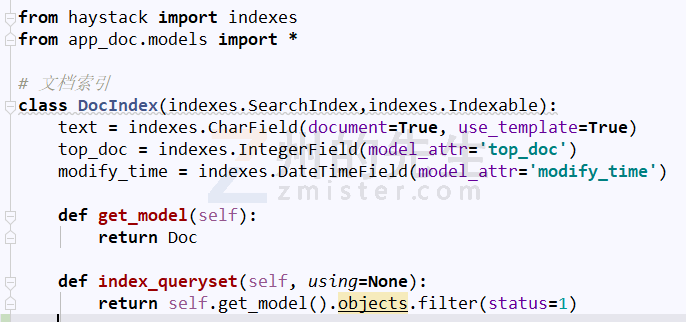
在 template 目录下新建一色名为 search 的目录,然后在 search 目录下新建一个名为 indexes 的目录,接着在其中新建一个名为 app_doc 的目录(与 Django 应用同名),最后在这个/template/search/app_doc 目录下新建一个名称 doc_text.txt 的文件(模型名称_text.txt),在其中输入需要索引的模型字段:
{{object.name}}
{{object.pre_content}}
创建中文分词器
由于 whoosh 对中文的分词能力不行,如果我们搜索中文,其八成不会对其进行分词,所以我们额外引入了 jieba 模块来进行中文分词。
在 /MrDoc/app_doc/search 目录下新建一个名为 chines_analyzer.py 的文件,在其中写入如下代码:
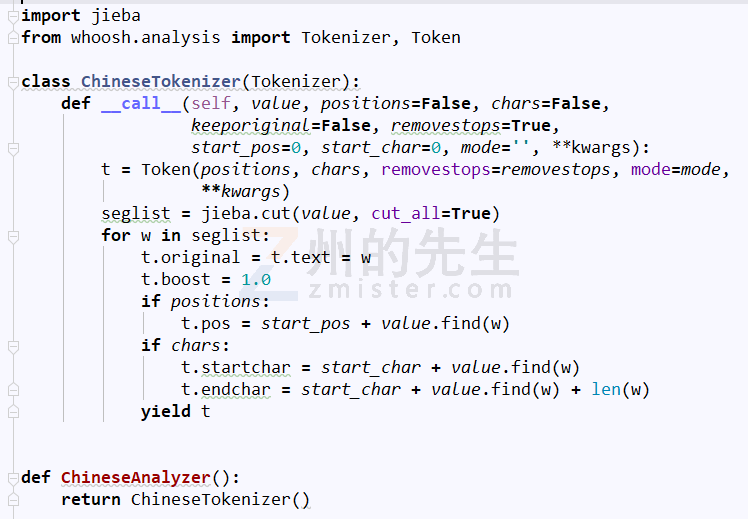
创建完中文分词器之后,我们就可以自定义 whoosh 的搜索引擎了。
自定义 whoosh 搜索引擎
在 /MrDoc/app_doc/search 目录下新建一个名为 whoosh_cn_backend.py 的文件(这个路径文件即是我们在 settings.py 文件中指定的引擎路径),复制 python 安装路径\Lib\site-packages\haystack\backends\whoosh_backend.py 的内容到这个文件中,并做如下修改:
from whoosh.analysis import StemmingAnalyzer
替换为:
from app_doc.search.chinese_analyzer import ChineseAnalyzer as StemmingAnalyzer
这样,我们自定义能够进行中文分词的 whoosh 引擎就完成了。
编写视图函数
完成上述步骤之后,全文搜索引擎幕后的工作就已经完成了,我们接下来需要按照 Django 的方式,编写逻辑视图,并进行 HTML 模板的渲染。
在这里,州的先生在/MrDoc/app_doc/下新建了一个名为 views_search.py 的文件来放置全文搜索的视图函数,继承 haystack.views.SearchView 类,自定义了一个全文搜索视图类:
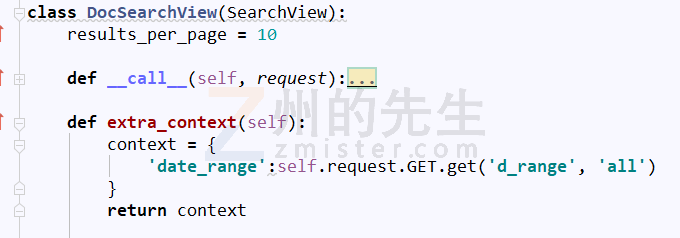
HTML 模板渲染
全文搜索引擎的数据默认返回在了特定的 HTML 模板中,州的先生没有对此进行自定义,所以按照 haystack 的要求,在 template/search 目录下新建了一个名为 search.html 的模板文件,对全文搜索视图类返回的搜索数据集进行渲染解析。

生成索引
最后我们需要在命令行终端生成一下索引文件,使用如下命令:
python manage.py rebuild_index
这样,就实现了纯 Python 方案的中英文全文搜索,效果如下动图所示:

文中所涉代码均为 MrDoc 觅道文档源码,包括:
/MrDoc/MrDoc/settings.py/MrDoc/app_doc/search/chinese_analyzer.py/MrDoc/app_doc/search/highlight.py/MrDoc/app_doc/search/whoosh_cn_backend.py/MrDoc/app_doc/search_indexes.py/MrDoc/app_doc/views_search.py/MrDoc/template/search/*
源码地址为:
- https://gitee.com/zmister/MrDoc
- https://github.com/zmister2016/MrDoc
文章版权所有:州的先生博客,转载必须保留出处及原文链接