一、回归预测
在前面的文章中我们介绍了机器学习主要解决分类、回归和聚类三大问题。今天我们来具体了解一下使用机器学习算法进行回归预测。
回归预测主要用于预测与对象关联的连续值属性,得到数值型的预测数据。回归预测的应用场景有各类的价格预测、相关性的反应预测等。
下面,我们就使用sklearn模块,以一个sklearn中集成的波士顿房价数据集来演示如何进行回归预测。
二、波士顿房价预测
1、引入数据集
在sklearn中内置的数据集都位于datasets子模块下,我们可以直接进行导入:
导入之后,看看数据集中的内容:
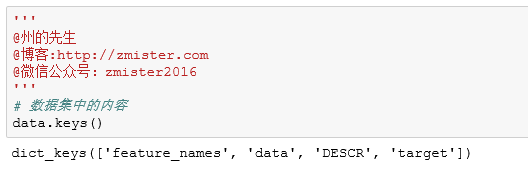
其中有五个键,从字面意思上理解,可以发现data是数据集中所有的数据特征,DESCR是数据集的描述信息,target是数据集特征对应的目标值,feature_name则是数据特征的名称。
我们先来看看数据特征的名称:

可以发现数据集中有13个特征,每个特征具体是什么意思,倒不清楚,我们可以在DESCR描述中找到具体意思:
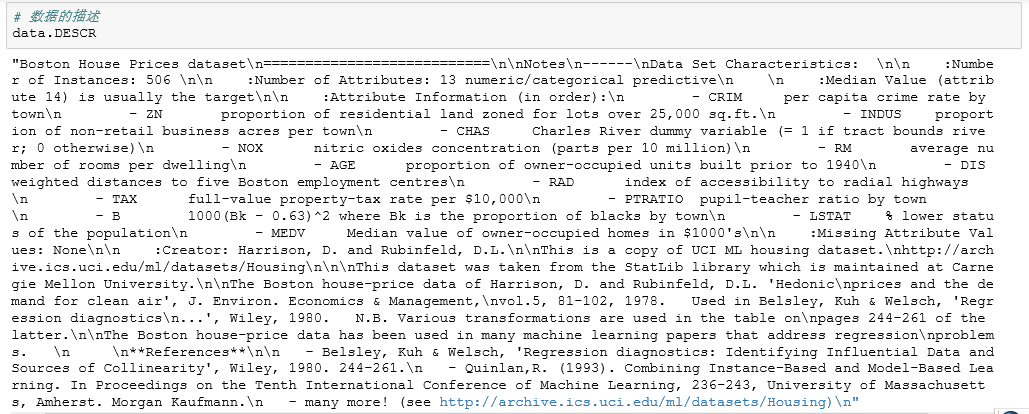
最后可以知道每个数据特征的含义如下:
- CRIM:人均犯罪率 ;
- ZN:住宅用地超过两万五千平方英尺的比例 ;
- INDUS:城镇的非零售营业比例;
- CHAS:河流分界;
- NOX:一氧化氮浓度 ;
- RM:住宅平均房间数;
- AGE:1940年之前建造的房屋业主比例;
- DIS:距离波士顿五个就业中心的加权距离;
- RAD:径向公路的可达指数;
- TAX :每一万美元财产的全额财产税率
- PTRATIO :城乡教师比例;
- B :黑人比例
- LSTAT :低层人群比例
- MEDV :房屋价格中值
再来看看具体的数据特征和目标数据值:
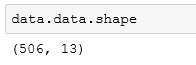
数据特征形状:
数据特征概览:

数据特征一共有506行,13列,正好对应13个数据特征。而目标数据值的也正好是506个:
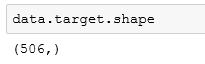
相当于是已经处理好的数据了。
但是对于初学者来说,这样处理好的数据看起来不是太直观,我们使用Pandas将其还原为DataFrame的形式,可以直观地看出这个数据集到底是什么样的:

对于熟悉使用pandas的同学来说,这样看这个数据集是不是亲切多了。
好了,我们可以直接进行下一步。
2、分割训练数据和测试数据
为了检验我们创建和训练好的机器学习模型的效果,将数据集分割为训练集和测试集是必须的。
而在sklearn中,也有一个专门的接口方法用于分割数据集的训练集和测试集——train_test_split,我们首先导入它:
![]()
然后将我们的数据集data传入,并设置测试集的比例为15%:

3、选择一个回归算法估计器
在sklearn中,所有的机器学习算法都以“估计器”的形式来呈现,每一个估计器都是一个类,机器学习模型通过实例化一个估计器的类来进行创建。比如线性回归的算法估计器:

每一个算法估计器,无论是监督学习算法还是非监督学习算法,都拥有一个fit()方法,用于接收训练数据集来训练数据,比如这样:

同时每一个算法估计器都有用一个predict()方法,用于接收数据来进行预测,比如这样:
![]()
在sklearn中,各类机器学习算法的API设计根据不同的用途的算法进行划分,我们可以方便地调用自己想要的算法,每一个监督学习算法,都由一个单独的子模块构成,其下包含算法的具体类,比如广义的线性回归算法:

其中根据用途,有的算法 可细分为用于回归的估计器和用于分类的估计器。
在此,我们选择随机森林算法的用于回归的估计器:
首先,导入算法估计器:
![]()
接着,实例化随机森林回归估计器,设置算法的参数并将训练集传入进行训练:

训练好模型之后,再使用predict()方法对训练集进行预测:

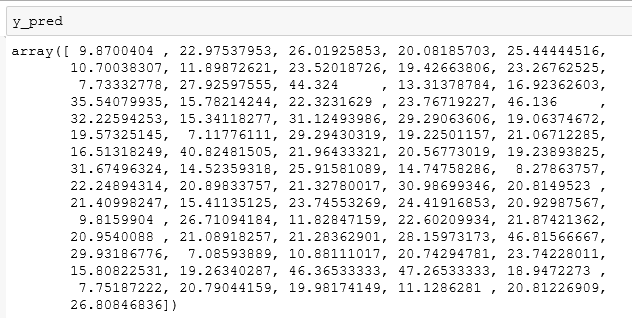
这样,我们就获得了使用随机森林回归模型对测试集进行预测的数据了,其为一个一维数组,我们可以直接打印出来看到:
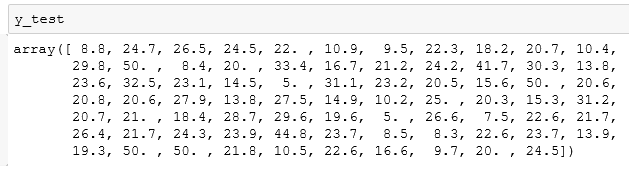
还记得我们分割训练测试集的时候,有过一个y_test的数组吧?它是测试集x_test数据特征对应正确的房价结果,我们也来看看其数据:
如何比较正确数组和预测出来的数组的值的正确度呢?一个比较蠢的方法是通过遍历这两个数组进行对比,查看其差值:
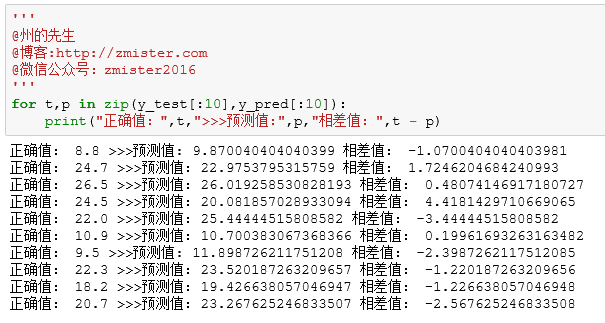
如果测试数据集少的话,这样来比较似乎工作量还不大,要是测试集很大那就没办法了。幸而,sklearn中也提供了对模型的评估方法,所有的评估方法都集成在sklearn.metrics子模块中。针对回归模型,我们可以使用平均绝对误差MAE和均方差MSE以及R2分数来对回归模型评估:

然后在评估方法中传入预测数组和正确数组:
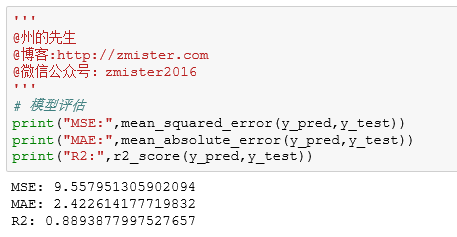
最终得到了我们的平均绝对误差值、均方差值和R2分数。其中,R2分数理论最佳值为1,平均绝对误差理论最佳值为0.0,均方差理论最佳值也为0.0,嗯,这个机器学习随机森林回归模型的效果如何?大家自己评估,也可以自己调用其他的回归模型来测试,看看哪个算法对这个数据集的预测效果较好。
下一篇,我们将创建一个用于分类的预测模型。
文章版权所有:州的先生博客,转载必须保留出处及原文链接
博主的文章很有帮助,但是图片损坏了,希望能够修复
多谢提醒