在上一章中,我们在Django项目中定义并生成了一个数据模型,在接下来的数据操作中,我们都会使用这个模型。
今天,我们来了解一下将Django的模型对象进行序列化和反序列化。
3.1、修改模型字段
在之前创建的模型中,我们只定义了5个字段,分别为:电影名称name、电影分类movie_cate、上映日期release_date、观看状态viewed和创建时间created。
经过考量,发现这几个字段还不足以展现出一个电影的基本信息来,所以在此我们对模型的字段进行一下扩充。在models.py文件中,在Movie类中多添加几个属性,最后的结果如下:
class Movie(models.Model):
name = models.CharField(verbose_name='电影名称',max_length=30)
movie_cate = models.CharField(verbose_name='电影分类',max_length=30,blank=True,null=True)
movie_img = models.CharField(verbose_name='封面图片',max_length=300,null=True,blank=True)
release_date = models.DateField(verbose_name='上映日期')
viewed = models.BooleanField(verbose_name='观看状态',default=False)
created = models.DateTimeField(verbose_name='创建时间',auto_now_add=True)
def __str__(self):
return self.name
class Meta:
verbose_name = '电影'
verbose_name_plural = verbose_name
ordering = ('name',)
接着按照上一章介绍的创建模型迁移和执行模型迁移的方法,完成对模型字段的添加:


最后,在数据库中可以发现,movies_movie表中已经多了一个字段:
3.1、采集和填充模型数据
在开始介绍序列化之前,我们先在先前创建的模型movies中填充一些电影数据。数据来源于哪里呢?我们充分发挥Python的用途,写一个简单的爬虫,采集猫眼电影的热映电影(http://maoyan.com/films?showType=1):
电影数据直接存在于网页源码中,所以我们采用requests+BeautifulSoup的采集方案,在当前项目movieapi的应用movies的目录下,新建一个名为utils的Python文件:
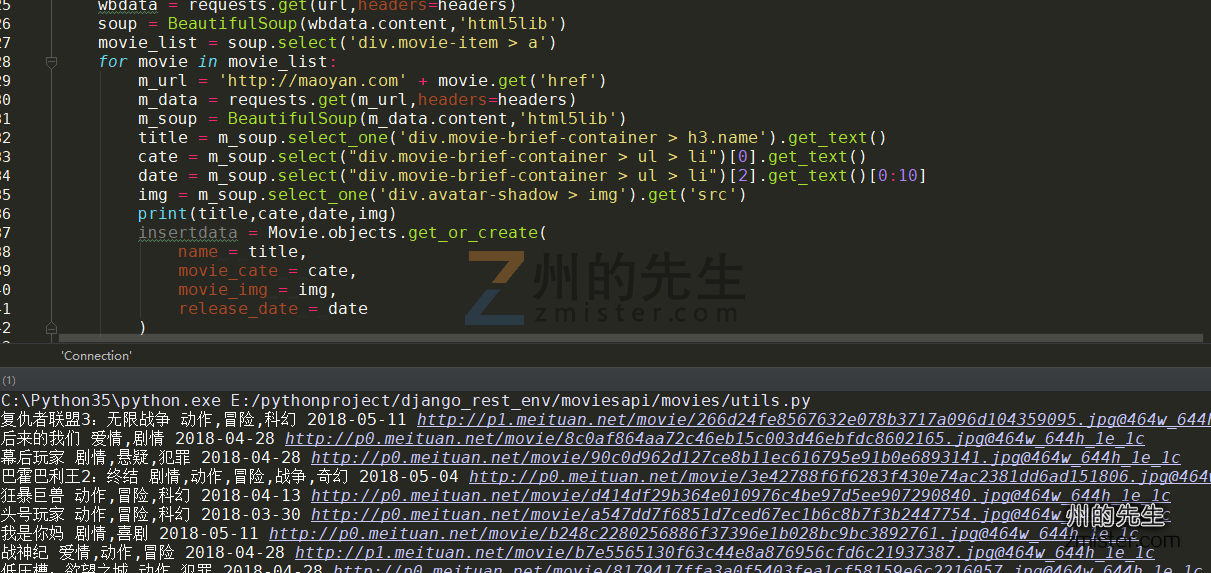
将以下代码写入:
# coding:utf-8
import requests,os,sys,django
from bs4 import BeautifulSoup
from django.core.wsgi import get_wsgi_application
sys.path.extend([r'E:/pythonproject/django_rest_env/moviesapi',])
os.environ.setdefault("DJANGO_SETTINGS_MODULE","moviesapi.settings")
application = get_wsgi_application()
django.setup()
from movies.models import Movie
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Host':'maoyan.com',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
def insert_data():
url = 'http://maoyan.com/films?showType=3'
wbdata = requests.get(url,headers=headers)
soup = BeautifulSoup(wbdata.content,'html5lib')
movie_list = soup.select('div.movie-item > a')
for movie in movie_list:
m_url = 'http://maoyan.com' + movie.get('href')
m_data = requests.get(m_url,headers=headers)
m_soup = BeautifulSoup(m_data.content,'html5lib')
title = m_soup.select_one('div.movie-brief-container > h3.name').get_text()
cate = m_soup.select("div.movie-brief-container > ul > li")[0].get_text()
date = m_soup.select("div.movie-brief-container > ul > li")[2].get_text()[0:10]
img = m_soup.select_one('div.avatar-shadow > img').get('src')
print(title,cate,date,img)
insertdata = Movie.objects.get_or_create(
name = title,
movie_cate = cate,
movie_img = img,
release_date = date
)
if __name__ == '__main__':
insert_data()
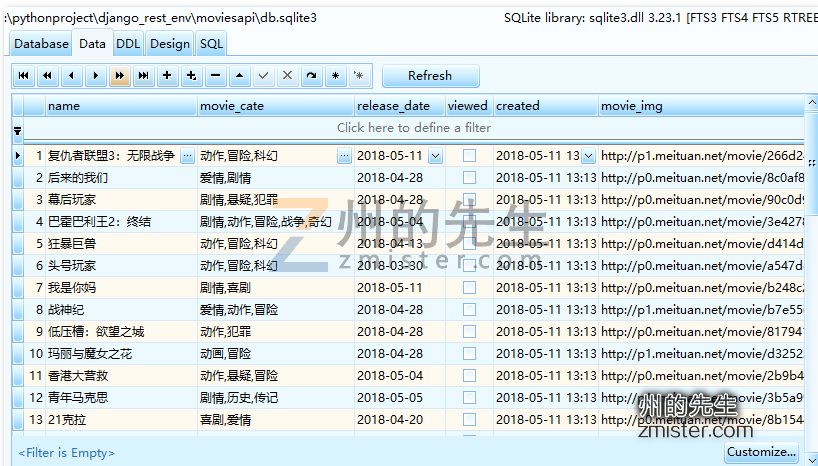
运行代码,我们就将页面中的电影信息写入到了数据库中:
从SQLite Expert软件中可以发现数据表中的数据更新了:
3.2、序列化和反序列化数据
数据表中的示例数据填充完成,我们就可以开始介绍数据的序列化和反序列化了。
什么是序列化和反序列化?我们知道,在Django中数据通过模型来表示,一份数据就是一个实例化一个模型具体方法的调用,其结果返回的是模型的实例对象。
我们可以进入Python Shell中进行测试一下:

在上图中,我们获取了Movie模型中name值为“后来的我们”的实例并赋值给变量a,a返回的则是一个Movie的实例对象。
如果我们使用了Django的模板,那么可以在上下文中将实例对象作为响应的一部分返回给浏览器。但是如果我们需要返回将其转化为JSON格式的数据返回给浏览器(比如咱们的restful服务),那么就需要进行序列化了。
序列化,就是将实例对象转换为可传输格式(JSON、XML等)的过程。反序列化则是序列化的反向过程。
通过django_rest_framwork模块的官方说明我们可以知道,Django Rest Framwork通过两个步骤来实现模型的序列化:
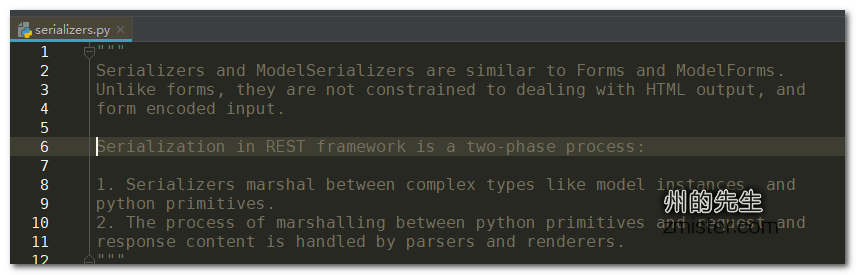
- 序列化器充当Django模型与Python原语之间的中介(就像Django模型充当数据库与Python之间的中介一样);
- 解析器和渲染器处理Python原语与http的请求响应之间的编码过程;
下面我们一一介绍序列化器和解析器、渲染器。
3.2.1、序列化器
在模块的serializers.py文件中,我们可以看到其定义的几个序列化器:
下面,我们通过创建一个Serializer类的子类来配置我们的第一个Movie模型的序列化器。在moviesapi/movies目录下新建一个名为serializers的Python文件:
我们创建的序列化器将在这个文件中进行定义,首先引入所需的模块:
# coding:utf-8
from rest_framework import serializers
from movies.models import Movie
然后创建一个继承于serializers.Serializer类的子类:
class MovieSerializer(serializers.Serializer):
# 声明模型的字段
pk = serializers.IntegerField(read_only=True)
name = serializers.CharField(max_length=30)
movie_cate = serializers.CharField(max_length=30)
movie_img = serializers.CharField(max_length=300)
release_date = serializers.DateField()
viewed = serializers.BooleanField(default=False)
# 声明模型创建的方法
def create(self, validated_data):
return Movie.objects.create(**validated_data)
# 声明模型更新的方法
def update(self, instance, validated_data):
instance.name = validated_data.get('name',instance.name)
instance.movie_cate = validated_data.get('movie_cate',instance.movie_cate)
instance.movie_img = validated_data.get('movie_img',instance.movie_img)
instance.release_date = validated_data.get('release_date',instance.release_data)
instance.viewed = validated_data.get('viewed',instance.viewed)
instance.save()
return instance
在上面创建的这个MovieSerializer类中,我们首先声明了模型中需要进行序列化的字段:
# 声明模型的字段
pk = serializers.IntegerField(read_only=True)
name = serializers.CharField(max_length=30)
movie_cate = serializers.CharField(max_length=30)
movie_img = serializers.CharField(max_length=300)
release_date = serializers.DateField()
viewed = serializers.BooleanField(default=False)
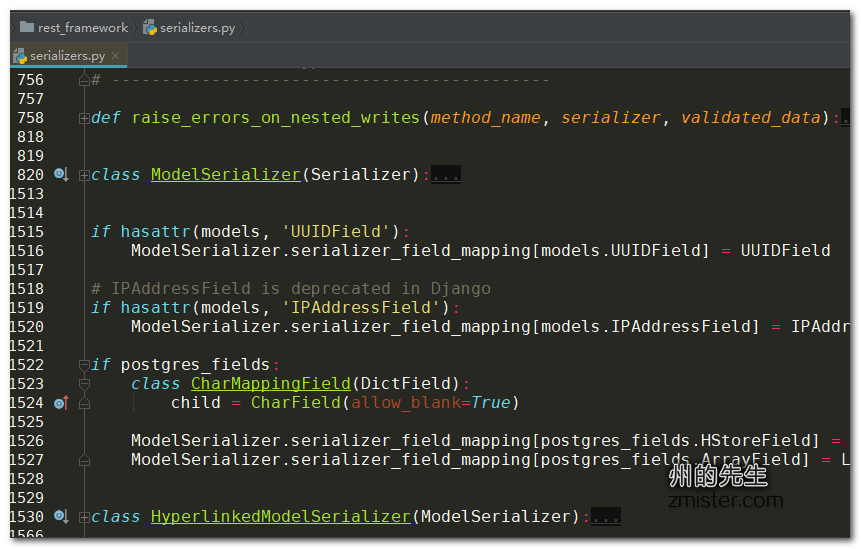
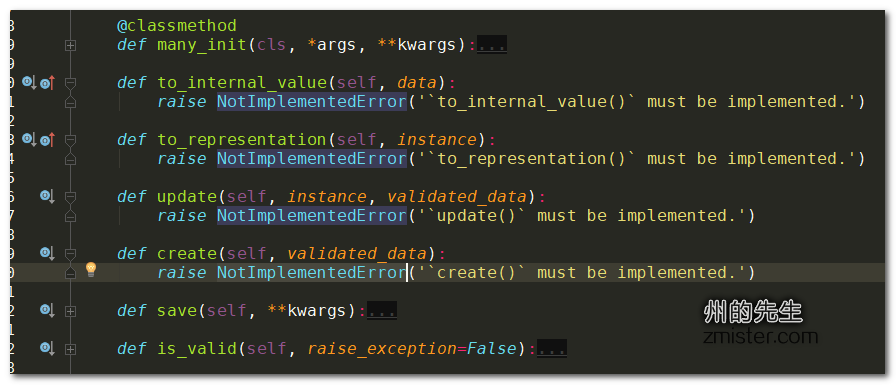
然后,重写了serializers.Serializer类中用于创建模型实例的create()方法和用于更新模型实例的update()方法。能不能不重写这些方法呢?答案是不能!因为这些方法在serializers.Serializer的基类BaseSerializer中,只声明了抛出一个NotImplementedError的异常,如下图所示:
接下来我们来看看这个MovieSerializer序列化器的效果,在命令行界面使用manage.py工具的shell命令打开Django的shell,命令如下所示:
python manage.py shell
进入到Django的Shell操作界面:
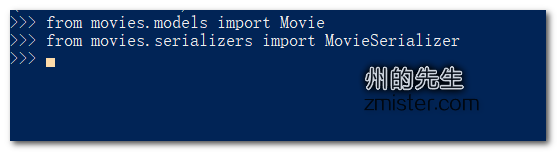
然后在shell中引入movie应用的Movie模型和MovieSerializer序列化器:
接着,我们获取两个模型的实例对象:

通过调用模型实例对象,我们可以看到,其返回的是模型对象的类型;调用模型实例对象的属性,其返回的则是具体的属性值:

现在我们调用序列化器MovieSerializer对这两个模型实例对象进行序列化操作:
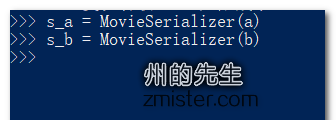
这样就完成了对模型实例对象的实例化,如何看到序列化后的数据呢?我们可以通过调用序列化器实例的data属性将序列化后的数据进行返回:

可以看到序列化器实例的data属性返回的就是Python标准的字典格式的数据了。
到此,我们的整个序列化过程完成了第一步,接下来需要使用到解析器和渲染器来完成序列化过程的第二步。
3.2.2、渲染器和解析器
渲染器和解析器用于处理HTTP的请求响应与Python原码之间的过程:
– 渲染器用于将响应序列化为特定的媒体类型以通过HTTP进行传输;
– 解析器用于解析传入HTTP请求的内容。
在Django Rest Framwork模块中,所有的渲染器都存在于rest_framework.renderer子模块下:
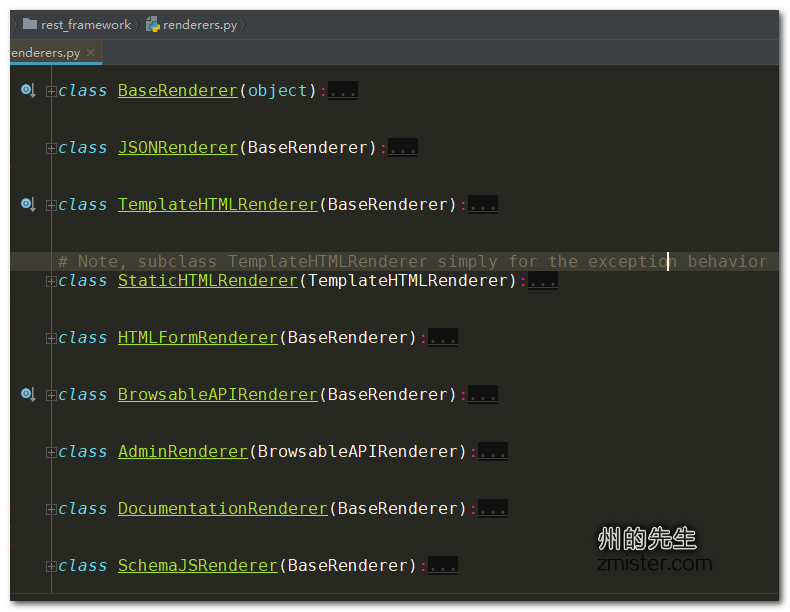
所有的解析器都存在于rest_framework.parsers子模块下:
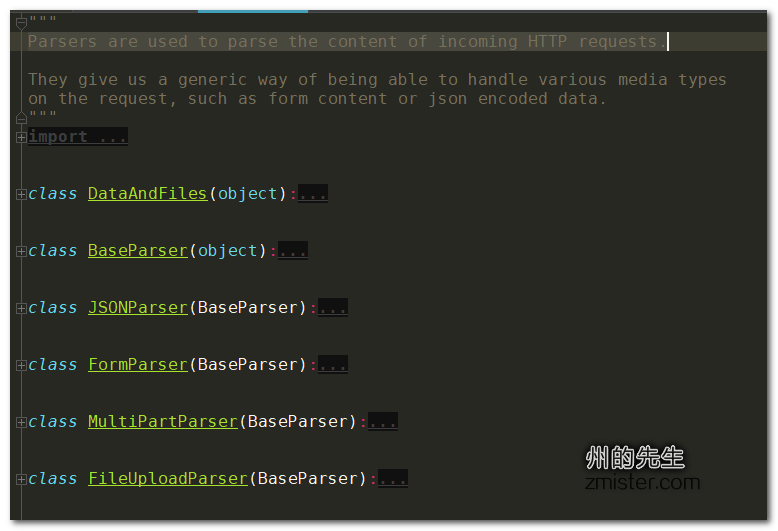
因为我们的项目是一个提供json格式数据的restful api服务,所以在此我们只介绍JSON渲染器和JSON解析器。
先来看看JSON渲染器的使用。首先引入模块:
from rest_framework.renderers import JSONRenderer
然后实例化一个JSONRenderer对象:
js_render = JSONRenderer()
最后,调用其render()方法进行渲染:
js_render.render(s_a.data)
结果返回了字节类型的JSON数据:

再来看看JSON解析器。
rest_framework.parsers下的JSONParser解析器主要通过其parse()方法对数据进行解析:
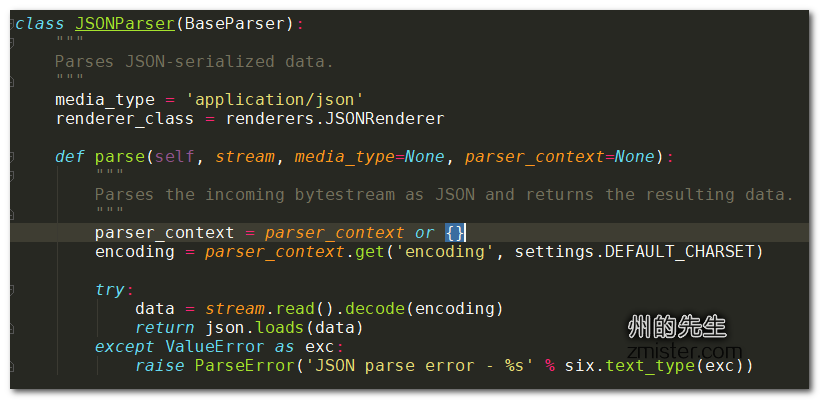
从Django Rest Framewokr的源码中我们可以看看,parse()方法将传入的字节流解析为JSON并返回生成的数据。我们来试验一下:
1.引入需要使用到的模块:
from rest_framework.parsers import JSONParser
from io import BytesIO
2.实例化一个JSONParser对象:
js_parser = JSONParser()
3.将JSON渲染器对变量s_a.data进行渲染生成的字节json数据赋值给一个变量js_a:
js_a = js_render.render(s_a.data)
4.创建一个内容的js_a的字节流:
byts_a = BytesIO(js_a)
5.调用JSON解析器的parse()方法对字节流进行解析:
js_parser.parse(byts_a)
结果返回的是Python的字典形式的数据:

3.3 本章小结
在本章,我们介绍了使用django-rest-framework模块对Django模型实例进行序列化和反序列化的方法。
在进行序列化操作之前,我们通过一些简单的爬虫采集了一些猫眼电影上的电影数据并写入到django模型中。
接着使用序列化器对象创建了一个基于Movie模型的序列化器,最后通过调用JSON渲染器和JSON解析器,完成了一个模型对象的序列化和反序列化。
文章版权所有:州的先生博客,转载必须保留出处及原文链接
instance.release_data = validated_data.get('release_data',instance.release_data):中的data应该是:date
已经修改,多谢指正
爬虫要进入根url 滑动验证后才得到数据