之前文章中所介绍的爬虫都是对单个URL进行解析和爬取,url数量少不费时,但是如果我们需要爬取的网页url有成千上万或者更多,那怎么办?
使用for循环对所有的url进行遍历访问?
嗯,想法很好,但是如果url过多,爬取完所有的数据会不会太过于耗时了?
对此我们可以使用并发来对URL进行访问以爬取数据。
一般而言,在单机上我们使用三种并发方式:
- 多线程(threading)
- 多进程(multiprocessing)
- 协程(gevent)
对于以上三种方法的具体概念解释和说明,各位可以自行网上搜索了解,相信会比我解释得清楚,所以在此就不对它们进行解释说明了。
本系列文章有两个重点,一个是实战,一个是入门,既为实战,理论性的东西就描述得比较少;既为入门,所讲述的都是简单易懂易操作的东西,高深的技术还请入门之后自行探索,那样也会成长得更快。
那么下面,开始并发爬取的实战入门,以多进程为例,并发爬取智联招聘的招聘信息。
一、分析URL和页面结构
1、搜索全国范围内职位名包含“Python”的职位招聘
我们不分职业类别、不分行业类别,工作地点选为全国,职位名为“Python”,对招聘信息进行搜索,结果如下图:
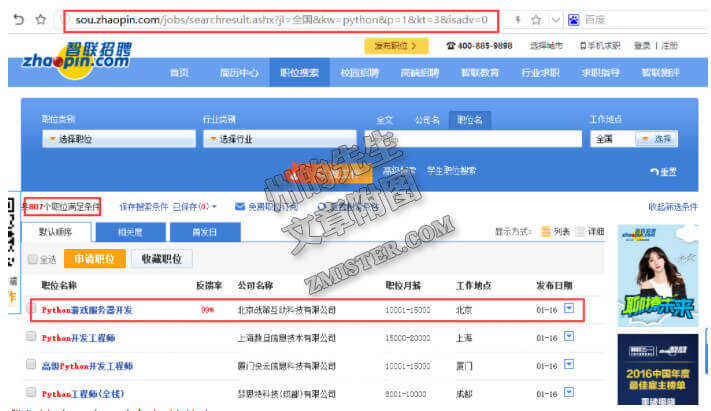
我们注意图中三个红框的信息:
- 搜索结果的url结构;(构造url地址进行for循环遍历)
- 搜索结果的条数;(判断url的数量)
- 采集的信息的主体;(解析数据)
通过筛选url参数,我们确定了需要爬取的基本URL为:
http://sou.zhaopin.com/jobs/searchresult.ashx?jl=全国&kw=python&kt=3&p=2
其中
http://sou.zhaopin.com/jobs/searchresult.ashx 为请求地址和目录
jl:工作地点参数
kw:搜索的关键字
kt:以职位名搜索
p:页数
我们可以发现,除了页数会变化之外,其余的参数值都是固定的值。我们来确定一下搜索结果的总页数。
因为网页上有提示一共有多少个职位满足条件,我们拿总职位数除以单页显示的职位数量即可知道搜索结果的页数。
# coding:utf-8
import requests
from bs4 import BeautifulSoup
import re
url = 'http://sou.zhaopin.com/jobs/searchresult.ashx?jl=全国&kw=python&p=1&kt=3'
wbdata = requests.get(url).content
soup = BeautifulSoup(wbdata, 'lxml')
items = soup.select("div#newlist_list_content_table > table")
count = len(items) - 1
# 每页职位信息数量
print(count)
job_count = re.findall(r"共<em>(.*?)</em>个职位满足条件", str(soup))[0]
# 搜索结果页数
pages = (int(job_count) // count) + 1
print(pages)
结果返回每页60条职位信息,一共有14页。
那么我们的待爬取的url地址就有14个,url地址中参数p的值分别从1到14,这么少的url,使用for循环也可以很快完成,但在此我们使用多进程进行演示。
二、在爬虫中使用多进程
先上代码:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
from multiprocessing import Pool
def get_zhaopin(page):
url = 'http://sou.zhaopin.com/jobs/searchresult.ashx?jl=全国&kw=python&p={0}&kt=3'.format(page)
print("第{0}页".format(page))
wbdata = requests.get(url).content
soup = BeautifulSoup(wbdata,'lxml')
job_name = soup.select("table.newlist > tr > td.zwmc > div > a")
salarys = soup.select("table.newlist > tr > td.zwyx")
locations = soup.select("table.newlist > tr > td.gzdd")
times = soup.select("table.newlist > tr > td.gxsj > span")
for name, salary, location, time in zip(job_name, salarys, locations, times):
data = {
'name': name.get_text(),
'salary': salary.get_text(),
'location': location.get_text(),
'time': time.get_text(),
}
print(data)
if __name__ == '__main__':
pool = Pool(processes=2)
pool.map_async(get_zhaopin,range(1,pages+1))
pool.close()
pool.join()
结果如下:

因为除了使用了多进程之外,其他的代码与之前文章介绍的方法大同小异,所以在此只介绍一下多进程的核心代码:
from multiprocessing import Pool
multiprocessing是Python自带的一个多进程模块,在此我们使用其Pool方法。
if __name__ == '__main__':
pool = Pool(processes=2)
pool.map_async(get_zhaopin,range(1,pages+1))
pool.close()
pool.join()
- 实例化一个进程池,设置进程为2;
- 调用进程池的map_async()方法,接收一个函数(爬虫函数)和一个列表(url列表)
如此,在爬虫中使用多进程进行并发爬取就搞定了,更多高级、复杂强大的方法,还请各位参考其他文档资料。
文章版权所有:州的先生博客,转载必须保留出处及原文链接
对了 请教一下,如果我想爬itunes上的app,但是没有找到可以获得所有app的网址的话,应该如何去做呢?
那个应该需要抓包找出url
嗯 谢谢
为什么说pages未定义
上下文两块代码是一起的,不要单独那后面那块代码来运行
我上下代码都合起来了,还是说pagess没有定义
pages = (int(job_count) // count) + 1 代码看仔细一点
回去试试看
伪元素,如div.clearfix里面的::before
我该怎么获取后面的span元素的内容?
看网页源码的结构,网页调试工具里面的可能会有差错
使用多进程好像前面几个进程页数是没有顺序的
Thanks very nice blog!
是的,不加的 话 这 就出错了,还不容易看出来是哪错了,我还是 print (str(soup)) 才知道根本就没收到网页内容
我运行怎么就出第几页,但是没有内容呢
检查一下有没有print
你这多线程好像有问题啊
我是按下面这个才跑的出结果,
from multiprocessing import Pool
def f(x):
return x*x
if __name__ == '__main__':
pool = Pool(processes=4)
#result = pool.apply_async(f, [10])
#print result.get(timeout=1)
#r=pool.map_async(f, range(10))
r=pool.map(f,range(10))
pool.close()
pool.join()
print(r)
map_async和map的区别和不同建议看看模块的说明
可不可以专门写一篇介绍多线程、多进程的专题文章?仅仅是一个例子很难理解啊
嗯,等有空了组织一下。其实也就是将Python的并发运用到爬虫上而已,网上廖雪峰的Python教程里面,对多进程、多线程和协程都讲的比较不错,容易理解,推荐看一看
-1
Traceback (most recent call last):
File "zlzz.py", line 16, in
job_count = re.findall(r"共(.*?)个职位满足条件", str(soup))[0]
IndexError: list index out of range
为什么会这样呢
你在网页上看看有没有那个元素,看看能不能定位到。这个错误表示正则表达式没有匹配发现到结果,返回了一个空列表,当然就会出现list index out of range.
没回传网页内容,正则匹配不到,你帮忙看下
同问 正则匹配不到.
匹配不到的,看看请求到的网页内容是什么,响应状态码是什么,多重分析
# coding:utf-8
import requests
from bs4 import BeautifulSoup
url = 'https://sou.zhaopin.com/jobs/searchresult.ashx?jl=%E5%85%A8%E5%9B%BD&kw=python&sm=0&p=1'
wbdata = requests.get(url).content
仅是这一句就一直报错,错误信息如下:
Traceback (most recent call last):
File "C:\Python\Python36\lib\site-packages\urllib3\connectionpool.py", line 601, in urlopen
chunked=chunked)
File "C:\Python\Python36\lib\site-packages\urllib3\connectionpool.py", line 387, in _make_request
six.raise_from(e, None)
File "", line 2, in raise_from
File "C:\Python\Python36\lib\site-packages\urllib3\connectionpool.py", line 383, in _make_request
httplib_response = conn.getresponse()
File "C:\Python\Python36\lib\http\client.py", line 1331, in getresponse
response.begin()
File "C:\Python\Python36\lib\http\client.py", line 297, in begin
version, status, reason = self._read_status()
File "C:\Python\Python36\lib\http\client.py", line 266, in _read_status
raise RemoteDisconnected("Remote end closed connection without"
http.client.RemoteDisconnected: Remote end closed connection without response
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Python\Python36\lib\site-packages\requests\adapters.py", line 440, in send
timeout=timeout
File "C:\Python\Python36\lib\site-packages\urllib3\connectionpool.py", line 639, in urlopen
_stacktrace=sys.exc_info()[2])
File "C:\Python\Python36\lib\site-packages\urllib3\util\retry.py", line 357, in increment
raise six.reraise(type(error), error, _stacktrace)
File "C:\Python\Python36\lib\site-packages\urllib3\packages\six.py", line 685, in reraise
raise value.with_traceback(tb)
File "C:\Python\Python36\lib\site-packages\urllib3\connectionpool.py", line 601, in urlopen
chunked=chunked)
File "C:\Python\Python36\lib\site-packages\urllib3\connectionpool.py", line 387, in _make_request
six.raise_from(e, None)
File "", line 2, in raise_from
File "C:\Python\Python36\lib\site-packages\urllib3\connectionpool.py", line 383, in _make_request
httplib_response = conn.getresponse()
File "C:\Python\Python36\lib\http\client.py", line 1331, in getresponse
response.begin()
File "C:\Python\Python36\lib\http\client.py", line 297, in begin
version, status, reason = self._read_status()
File "C:\Python\Python36\lib\http\client.py", line 266, in _read_status
raise RemoteDisconnected("Remote end closed connection without"
urllib3.exceptions.ProtocolError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:/Users/Administrator/PycharmProjects/Start/pqzhilian.py", line 8, in
wbdata = requests.get(url).content
File "C:\Python\Python36\lib\site-packages\requests\api.py", line 72, in get
return request('get', url, params=params, **kwargs)
File "C:\Python\Python36\lib\site-packages\requests\api.py", line 58, in request
return session.request(method=method, url=url, **kwargs)
File "C:\Python\Python36\lib\site-packages\requests\sessions.py", line 508, in request
resp = self.send(prep, **send_kwargs)
File "C:\Python\Python36\lib\site-packages\requests\sessions.py", line 618, in send
r = adapter.send(request, **kwargs)
File "C:\Python\Python36\lib\site-packages\requests\adapters.py", line 490, in send
raise ConnectionError(err, request=request)
requests.exceptions.ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',))
URL请求失败,看看网页有没有问题
在request的get方法中加入headers,模拟浏览器行为,即可进行抓取。于19.1.18,12.56
{"salary": "8001-10000", "company": "亿帆环球科技(济南)有限公司", "name": "Linux C软件开发工程师 ", "location": "济南"}
{"salary": "6001-8000", "company": "", "name": " ", "location": "无锡"}
{"salary": "面议", "company": "无锡际扬科技有限公司", "name": "VR游戏设计师助理 ", "location": "北京"}
{"salary": "10000-20000", "company": "", "name": " ", "location": "成都"}
想把抓取的数据存到mysql,结果字段没晒出来,不知道怎么解决,大神能把这段补上吗
其他文章有涉及数据库存储
pool.map_async(get_zhaopin,range(1,pages+1))
页数参数好像没有传进去,调用函数的时候没有执行
pool.map_async(get_zhaopin(1),range(1,pages+1))
的时候会显示第一页,所以好像有问题这句话,您能帮我解答一下吗,从网上找解决方法说的是用result.get()试了一下依然没有用
在Linux下跑没有问题,但是Windows下就没有print,你的是windows对吗
就是在Windows上运行的
加我微信私聊
我把参数改到上海用你的代码,爬取到的每页数量小于实际数量,页数大于实际页数
我把参数改为上海,查询的每页数量小于实际数量,查询的页数大于实现页数