
PyQt5的PyQtGraph实践系列1:添加图形到PyQt5布局
1、使用PyQtGraph绘制折线图 在pyqtgraph中,我们可以直接简单快速地绘制一个基本的图形出来。比如下面这样: import pyqtgraph a…

Python可视化对比分析淘宝低价人群和匿名用户的淘宝连衣裙数据
1、我是一个低价人群用户 上周发表文章《一个匿名用户的淘宝“连衣裙”大观》后,交流群里面很热闹地讨论了起来,小伙伴们都在秀自己的淘宝连衣裙搜索价格,相较于小伙伴…

一个匿名用户的淘宝“连衣裙”大观 | 可视化探索淘宝“连衣裙”商品数据
一、匿名用户 我是一个匿名用户,我遍布全国各地。我在互联网上来去自如、行动洒脱,从不喜欢登录。如果哪家网站让我登录,我就……不使用它。 最近听闻在淘宝上搜索“连…
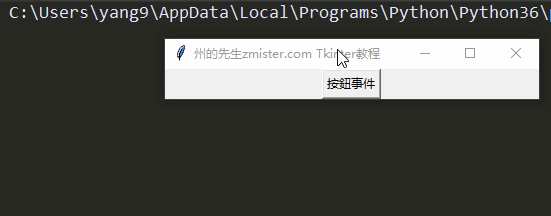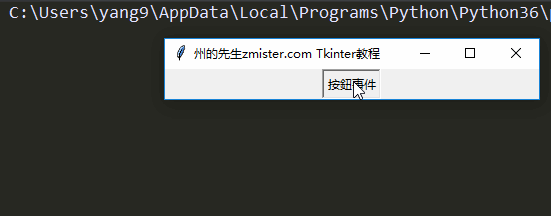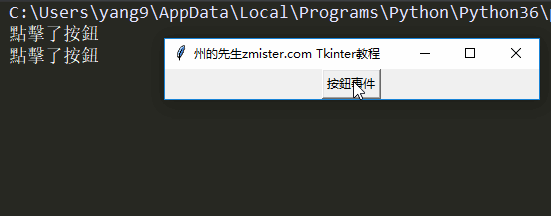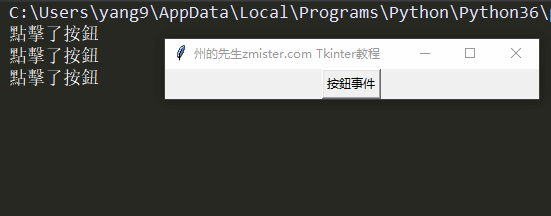
实例讲解Tkinter键盘与鼠标事件处理|先生的Tkinter教程(5)
一、事件处理的重要性 能够对事件进行反应和处理是图形界面程序开发过程中最重要的任务之一,因为只有事件处理才能让一个图形界面程序拥有灵魂,否则,图形界面程序只是一…
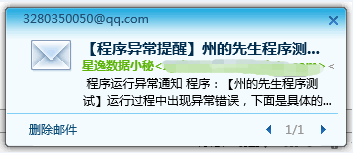
简洁Python程序运行异常邮件提醒
一、前言 有一天,你眼疾手快写好了一个Python程序来处理大批量的任务,然后信心满满地点击“Run”按钮,想着任务量巨大,可能需要计算机处理一段时间,于是带着…

实例讲解Tkinter数值与文本选择小部件|先生的Tkinter教程(4)
一、前言 在图形界面开发中,除了按钮和文本输入框外,各种选择框也是必不可少的组件。为了确保用户输入的准确性,很多内容我们不方便让用户自行输入,转而使用各种预置好…

【代码+数据】Python采集《毛选5》并保存为xhtml文件
一、关于毛选5 《毛泽东选集》第5卷是毛泽东1949年以后著作的选集。这本书的编辑、出版用了近十年的时间,时间贯穿了整个文革。 由于特殊原因,这本书在1982年…
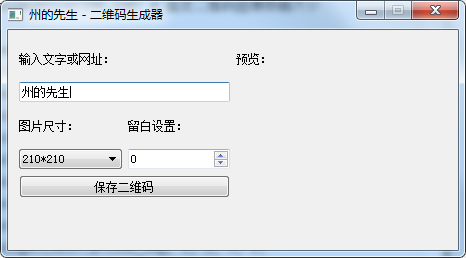
Python图形界面实战:使用PyQt5/PiSide2制作二维码生成器
一、文中涉及 本文涉及以下知识点: PyQt5/PiSide2网格布局的使用; PyQt5/PiSide2按钮小部件的使用; PyQt5/PiSide2标签小部…
Tkinter单行文本输入Entry小部件|先生的Tkinter教程(3)
零、前文回顾 《创建第一个Tkinter图形界面|先生的Tkinter教程(1)》 《Tkinter按钮部件的花样呈现|先生的Tkinter教程(2)》 一、创…
【数据采集实例分析】网页复杂渲染机制下的数据解析
一、前言 在进行数据采集的过程中,我们遇到的很多网页所采用的都是比较单一的页面渲染方法。比如: 后端直接返回HTML; 前端请求数据接口进行渲染; 对于采用第一…

Tkinter按钮部件的花样呈现|先生的Tkinter教程(2)
在上一篇文章《创建第一个Tkinter图形界面|先生的Tkinter教程(1)》中,我们学习并创建了一个最基本的Tkinter图形界面程序。这个图形界面程序中只…

实战|使用PyQt5制作BT种子转磁力链接工具
一、种子文件与磁力链接 经常下载各种资源和影视资料的小伙伴对于BT种子应该是不陌生的,通过小小的BT种子,我们可以下载到各种丰富的资源。而磁力链接相较于BT种子…

创建第一个Tkinter图形界面|先生的Tkinter教程(1)
一、为什么使用Tkinter而非PyQt 众所周知,在Python中创建图形界面程序有很多种的选择,其中PyQt和wxPython都是很热门的模块包,这些第三方…

演示 | 突破淘宝滑块验证,Selenium直接登陆淘宝
前言 众所周知,阿里系的反爬虫技术一直都是业内一流的,随着反爬虫手段的不断加强,淘宝的登录从Selenium操纵webdriver直接登录,到Selenium模…