标签:Python
【我爱背单词】用Python提炼3000英语新闻高频词汇
学英语,无论目的何在,词汇量总是一个绕不过去的坎,没有足够的词汇量,都难以用文法来组词造句。 前段时间,恶魔的奶爸提供了几份偏向于各个领域的高频词汇,很是不错。…

Python爬虫实战入门五:获取JS动态内容—爬取今日头条
之前我们爬取的网页,多是HTML静态生成的内容,直接从HTML源码中就能找到看到的数据和内容,然而并不是所有的网页都是这样的。 有一些网站的内容由前端的JS动态…

Python爬虫实战入门四:使用Cookie模拟登录——获取电子书下载链接
在实际情况中,很多网站的内容都是需要登录之后才能看到,如此我们就需要进行模拟登录,使用登录后的状态进行爬取。这里就需要使用到Cookie。 现在大多数的网站都是…

Python爬虫实战入门二:从一个简单的HTTP请求开始
一、为什么从HTTP请求开始 无论我们通过浏览器打开网站、访问网页,还是通过脚本对URL网址进行访问,本质上都是对HTTP服务器的请求,浏览器上所呈现的、控制台…

Python爬虫实战入门一:工具准备
一、基础知识 使用Python编写爬虫,当然至少得了解Python基本的语法,了解: 基本数据结构 数据类型 控制流 函数的使用 模块的使用 不需要过多过深的P…
如何提高爬虫效率?Python下简单的进程、线程效率对比
在爬取海量的网络数据时,一方面我们需要确保爬虫不被网站服务器封掉,一方面也要提高爬虫的采集效率。 避免爬虫不被封掉,一般我们通过大量的代理IP构成代理池,通过代…

爬取百度音乐5000热门歌单10万音乐数据
平时喜欢用百度音乐随便找个歌单听听歌,一来搜索打开方便,二来歌曲曲目也全。今天在找歌单的时候,突然想看看热门歌单里都有哪里歌曲,于是便有了这个小程序。 首先,需…

【数据集】100万以大学专业为关键词的职位数据
数据源自之前的爬虫所爬取的数据,数据一共100多万条,有5个字段:时间、地点、职位名称、月薪、专业名称,可以用来做大学专业的一些统计分析; 部分截图如下: &n…

加盟创富好项目?简单可视化分析告诉你78网上到底都有啥!
数据来源于本月早些时候从78网上爬取到的768份数据,数据量不大,但是可以深入挖掘的地方还是有不少的,由于时间关系,在此只作简单的数据处理和可视化分析; 一、数…
在Pandas中直接加载MongoDb的数据
在使用Pandas进行数据处理的时候,我们通常从CSV或EXCEL中导入数据,但有的时候数据都存在数据库内,我们并没有现成的数据文件,这时候可以通过Pymong…
Python爬虫:100万以大学专业为关键词的职位信息爬取
一、系统环境: Windows 7+Python3.4+MongoDB 二、爬取过程: (1)获取大学本科所有专业名称 # 获取大学本科专业名称 def get…
一个简单的多进程爬虫(爬取某加盟创业网)
分享一个简单的多进程小爬虫,爬取某加盟创业网上所有加盟项目; 使用requests请求页面,re和beautifulSoup解析网页,multiprocessi…

运用汽车数据进行Python可视化分析
数据来源 vehicles.csv是一份来自于www.fuelconomy.gov 的数据,它包含了美国各个汽车制造商各个型号汽车不同时间点的油耗表现参数和各个…
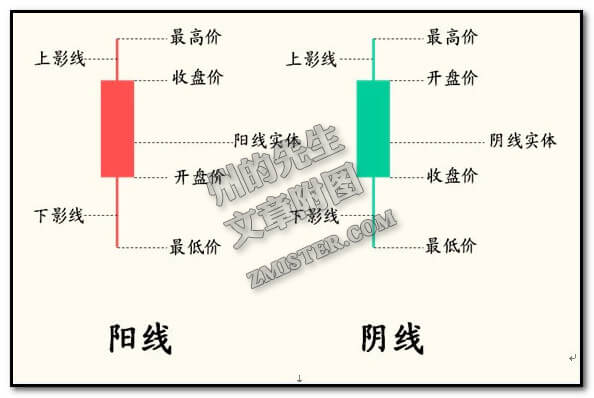
使用Matplotlib轻松绘制股票K线图
K线图是看懂股票走势的最基本知识,K线分为阴线和阳线,阴线和阳线都包含了最低价、开盘价、最高价和收盘价,一般的K线如下图所示: 度娘说:K线图源于日本德川幕府时…