各省的公务员考试都已经进入了报名阶段,很多报考了的同学也都在准备进行行测和申论的复习备考。
对于申论,很多同学都会选择一边做题一边看新闻联播、人民日报等官方媒体渠道的方式来备考。
多阅读和观看新闻联播、人民日报等官方媒体,可以提高对时政的掌握,以及了解官方对某些事物的具体态度。
而人民日报时评和社论对文章的构造、用语手法、专业术语的使用,对写作或是基础常识都会有很好的辅助效果。
聊胜于无,使用Python编写了一个简单的采集工具,从人民网的人民时评(http://opinion.people.com.cn)中爬取了最新的200篇人民时评,并保存为txt文本文件,方便大家在移动设备上进行阅读。
具体代码如下:
# coding:utf-8
'''
@ author:州的先生
@ site:http://bxu2713810459.my3w.com
@ 微信公众号:州的先生
'''
import requests
from bs4 import BeautifulSoup
import time
n = 1
for p in range(1,5):
list_url = 'http://opinion.people.com.cn/GB/8213/353915/353916/index{0}.html'.format(p)
list_wbdata = requests.get(list_url).content
list_soup = BeautifulSoup(list_wbdata,'html5lib')
list_link = list_soup.select("td.t11 > a")
for l in list_link:
page_href = l.get('href')
page_title = l.get_text()
print(page_title,page_href)
page_url = 'http://opinion.people.com.cn'+ page_href
page_wbdata = requests.get(page_url).content
page_soup = BeautifulSoup(page_wbdata,'html5lib')
content = page_soup.select_one("div.box_con")
with open('{0}.txt'.format(page_title),'a+', encoding='utf-8',newline='') as files:
files.writelines(content.get_text())
print("写入完成!",n)
n += 1
time.sleep(2)一共采集并保存了200篇时评文章,每篇一个txt文件。
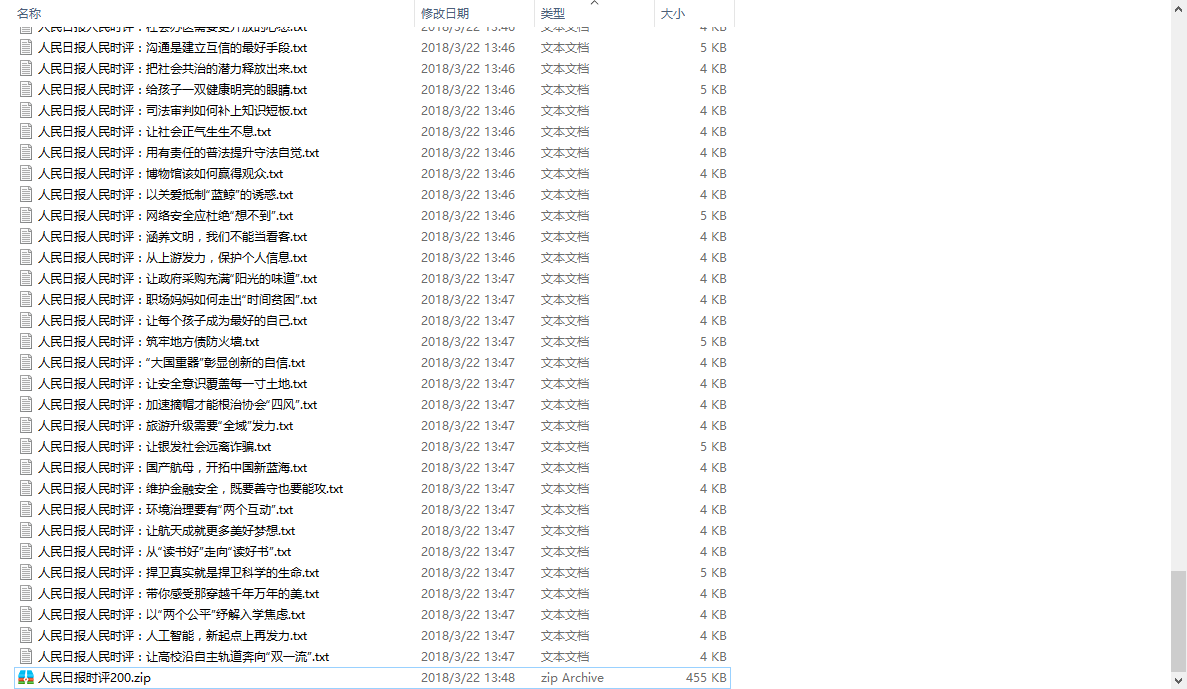
大家可以使用上面的代码进行采集,或者获取关注我的微信公众号:州的先生,回复关键字:人民日报时评 获取打包好的文集。
文章版权所有:州的先生博客,转载必须保留出处及原文链接