Python爬虫入门实战八:数据储存——MongoDB与MySQL
好久没更新了,今天填一个坑。
前面的文章里写的爬虫都是直接把爬取的数据打印出来。在实际的应用中,当然不能这么做,我们需要将数据存储起来。存储数据的方式有很多中,比如存储在文本文件中,或者是存储在数据库中。
为了使用数据的便捷性,我们选择将数据存储在数据库中。
数据库主流的两种类型为:SQL(关系型数据库)和NoSQL(非关系型数据库)
我们在此选用使用比较广泛的MySQL和MongoDB作为讲解
一、MySQL
1、安装MySQL
由于MySQL的安装文件比较大且配置稍微繁琐,个人推荐在普通环境下使用集成包,比如USBWebserver。
USBWebserver其实是一款傻瓜式本地电脑快速架设PHP网站环境的工具,它最大特色是纯绿色便携,可直接放在U盘里随处运行它集成了 Apache (httpd)、PHP、MySQL 以及 PHPMyAdmin 等组件,而我们使用它的MySQL即可。

打开程序之后,看到Mysql运行成功,就可以打开PHPMyAdmin
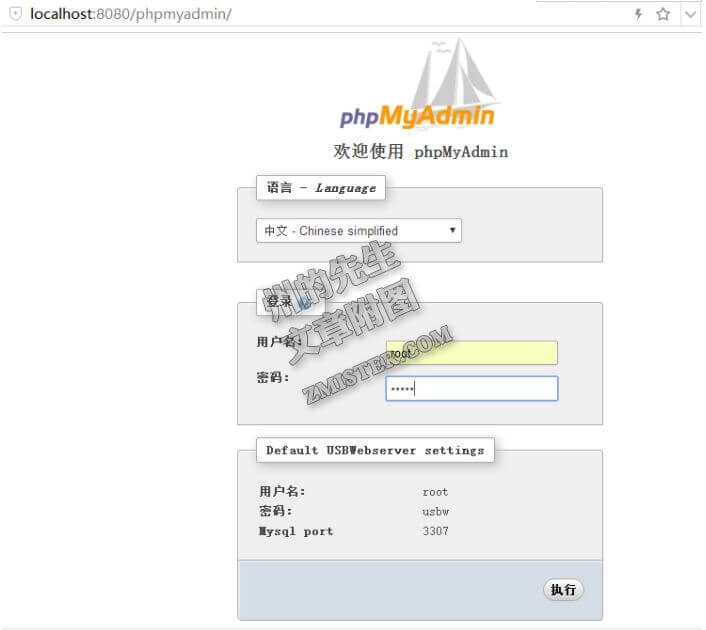
点击执行,进入控制页面
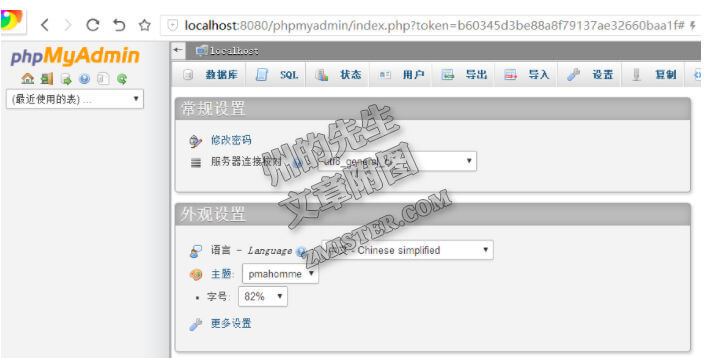
就可以在里面创建数据库,创建数据表了。
更多介绍及下载:http://www.iplaysoft.com/usbwebserver.html
2、安装pymysql
在Python中使用MySQL,有两种方式,使用ORM(对象关系映射)框架和数据库模块,在此我们使用数据库模块pymysql(Python3)。
安装pymysql:
pip install pymysql
3、在爬虫程序中使用mysql
我们以之前爬取今日头条的例子来扩展;
之前的代码是这样的:
# coding:utf-8 import requests import json url = 'http://www.toutiao.com/api/pc/focus/' wbdata = requests.get(url).text data = json.loads(wbdata) news = data['data']['pc_feed_focus'] for n in news: title = n['title'] img_url = n['image_url'] url = n['media_url'] print(url,title,img_url)
在最后,我们直接使用print将数据打印了出来。
现在我们使用pymysql将数据存储到Mysql中。
(创建数据库toutiao,创建数据表data)
修改的代码如下:
# coding:utf-8 import requests import json import pymysql conn = pymysql.connect(host='localhost',port=3307,user='root',password='usbw',db='toutiao',charset='utf8') cursor = conn.cursor() url = 'http://www.toutiao.com/api/pc/focus/' wbdata = requests.get(url).text data = json.loads(wbdata) news = data['data']['pc_feed_focus'] for n in news: title = n['title'] img_url = n['image_url'] url = n['media_url'] print(url,title,img_url) cursor.execute("INSERT INTO data(title,img_url,url)VALUES('{0}','{1}','{2}');".format(title,img_url,url)) conn.commit() cursor.close() conn.close() 最后,数据库中就已经存储了数据:
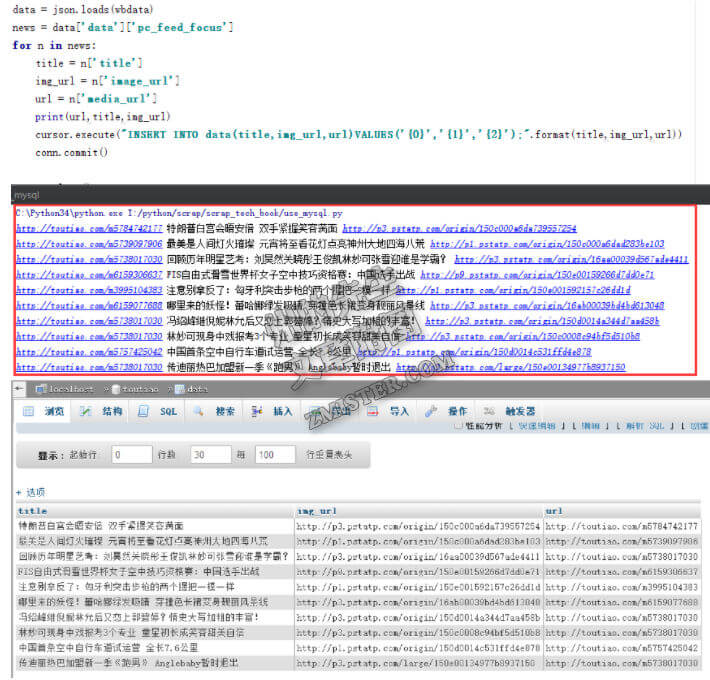
与之前的代码相比,有以下不同:
引入pymysql模块:
import pymysql
建立一个mysql的连接:
conn = pymysql.connect(host='localhost',port=3307,user='root',password='usbw',db='toutiao',charset='utf8')
创建一个游标cursor:
cursor = conn.cursor()
执行一个SQL语句:
cursor.execute("INSERT INTO data(title,img_url,url)VALUES('{0}','{1}','{2}');".format(title,img_url,url)) 提交执行(因为对数据进行和修改,如果只是select,则不需要):
conn.commit()
最后,关闭连接:
cursor.close() conn.close()
嗯,将数据保存在MySQL就完成了,更多的MySQL和PyMySQL的用法,还请看文档
下面看看MongoDB
二、MongoDB
1、下载并安装MongoDB:
https://www.mongodb.com/download-center
2、运行mongodb:
进入安装好之后的mongo目录的bin目录,打开命令行窗口,输入“mongod –dbpath=数据存放路径”

3、安装pymongo:
pip install pymongo
4、使用MongoDB和PyMongo
依然是扩展爬取今日头条的例子,先上代码:
# coding:utf-8 import requests import json import pymongo conn = pymongo.MongoClient(host='localhost',port=27017) toutiao = conn['toutiao'] newsdata = toutiao['news'] url = 'http://www.toutiao.com/api/pc/focus/' wbdata = requests.get(url).text data = json.loads(wbdata) news = data['data']['pc_feed_focus'] for n in news: title = n['title'] img_url = n['image_url'] url = n['media_url'] data = { 'title':title, 'img_url':img_url, 'url':url } newsdata.insert_one(data) for i in newsdata.find(): print(i) 存储数据到MongoDB并读取出来

Pymongo相关的代码为:
引入模块
import pymongo
连接到Mongo
conn = pymongo.MongoClient(host='localhost',port=27017)
选择或创建数据库
toutiao = conn['toutiao']
选择或创建数据集合
newsdata = toutiao['news']
插入一行数据:
newsdata.insert_one(data)
查询数据
newsdata.find()
如此,简单地对数据进行数据库存储就完成了。